QCon 2026·快猫星云:从 AIOps 到 AgentOps 的故障定位实践
主讲:裴彤(快猫星云,AI 产品研发负责人)
主持:秦晓辉(快猫星云创始人)
时长:约 54 分钟
用 Agent 来解决 Ops 的问题,而不是用 Ops 管理 Agent。快猫星云分享了可观测知识图谱 + AI Agent 做故障定位的完整实践,包括图谱自动化构建、四种 Agent 使用策略、Harness 工程和多 Agent 协作架构。
主持人开场
核心其实是大家能把问题说清楚、把任务拆解好,事情就解决了。过去几个月乃至去年,更多是代码层面的”aha moment”——写代码越来越快,新想法落地周期越来越短,但生产环境的代码膨胀速度也越来越快。所以这时候需要更多偏运维层面的手段来应对。
今天的主题是 AgentOps。这个词容易产生混淆,先澄清一下:AgentOps 有两种理解,一种是用 Ops 的手段解决 Agent 的运维问题——很多公司现在有大量 Agent,比如美图说他们搞了 820 个龙虾,各种公司都在疯狂增长,所以有一个方向是用 Ops 手段管理这些 Agent。但今天我们探讨的不是这个,而是如何用 Agent 来解决 Ops 的问题,用少量几个 Agent 解决运维层面的难题。
Coding 场景相对好做,因为上下文非常清晰——你要写什么代码,code base 可以很容易地被 AI 拿到。但在 Ops 领域,信息零散、不规整,AI 把这么多数据放在一起分析非常困难,所以这个问题更难解决。
我叫秦晓辉,可能很多人没听过。2002 到 2014 年前后,大家可能用过 Open-Falcon,后来还有夜莺监控,这是国内最知名的两个监控领域开源项目,都出自我手。现在我在可观测性领域创业,核心帮用户解决可观测性和故障定位的问题。
整体来看,现在市场上各头部企业——Datadog、Dynatrace、SRM,以及专门做 RCA 的 CausalRCA 等——都在往这个方向使劲。这个领域比 AI Coding 稍微滞后一些,但其中最有意思的就是 RCA(根因分析)。做 AI 聊天窗口、梳理知识库相对简单;把各种数据综合起来解决故障定位,才是真正复杂的挑战。这里面要考虑上下文窗口爆掉怎么办、数据不规整怎么串联、metrics/logs/traces/profiling 语义规范不统一怎么处理,以及大模型幻觉——信誓旦旦说找到根因了,其实毫无数据依据。
今天我们有三位讲师分享落地实践。第一位是来自快猫星云的裴彤,之前一直做推荐算法,后来转到运维领域做 RCA 实践。有请裴东。
主讲:AgentOps 故障定位实践
背景:从 AIOps 到 AgentOps 的演进
大家好,我是裴彤,来自快猫星云,目前在做 AIOps 相关工作。
说到 AIOps 这个话题,大家应该不陌生。早在 ChatGPT 火爆之前,大概七八年前,业界就已经在做所谓的 AIOps。这个演进可以分为四个阶段:
| 阶段 | 代表技术 | 人机关系 |
|---|---|---|
| 传统监控,可观测性起点 | Dashboard、人工分析 | Data for Human |
| AIOps 时代 | 异常检测、告警降噪、根因维度分析 | AI assists Human |
| 引入大模型阶段 | Copilot、AI 问答、Workflow 自动化 | Human + AI 协同 |
| 以 Agent 为核心的运维系统 | Agent、Tool/Skill、ReAct、Planning | AI takes actions |
以前的 AIOps 本质上是在特定数据集、特定场景下做维度分析,辅助人类决策,并不是真正意义上”拿到任何业务系统就能自动定位故障”。那个时代仍然以人为主,算法只是辅助。
到了大模型时代,大家开始把大模型引入故障定位和运维流程,最初是做 workflow、AI 问答,而现在我们认为有了 AI Agent 这种形态,才真正有可能实现 AIOps 的目标。这个目标有三点:
- 数据建设的智能化
- 数据应用的智能化
- 系统交互的智能化

核心方案:可观测知识图谱
为什么单纯接入 AI Agent 不够用?
首先,AI Agent 缺少推理依据。企业级场景下日志指标量巨大,不可能把所有日志、所有指标全塞进大模型——上下文直接爆掉。其次,模型不知道 A 服务告警和 B 服务有什么关系,关联关系不清楚。另外会急剧放大幻觉——大模型倾向于顺着你的意图说,你问它”这个有什么问题”,它可能无中生有给你找出问题来。最终结论会误导人:有经验的工程师会说”我只是猜测”,但大模型会斩钉截铁给你一个结论,往往误导故障分析。
只有 metrics、logs、traces 的时候,模型既不知道谁依赖谁,也不知道一个服务是干什么的,更不知道异常如何传播。
解决方案:可观测知识图谱
知识图谱的概念不新鲜,传统 AIOps 时代也有人提,但到了大模型 + AI Agent 时代,它天然适合作为推理的基础。
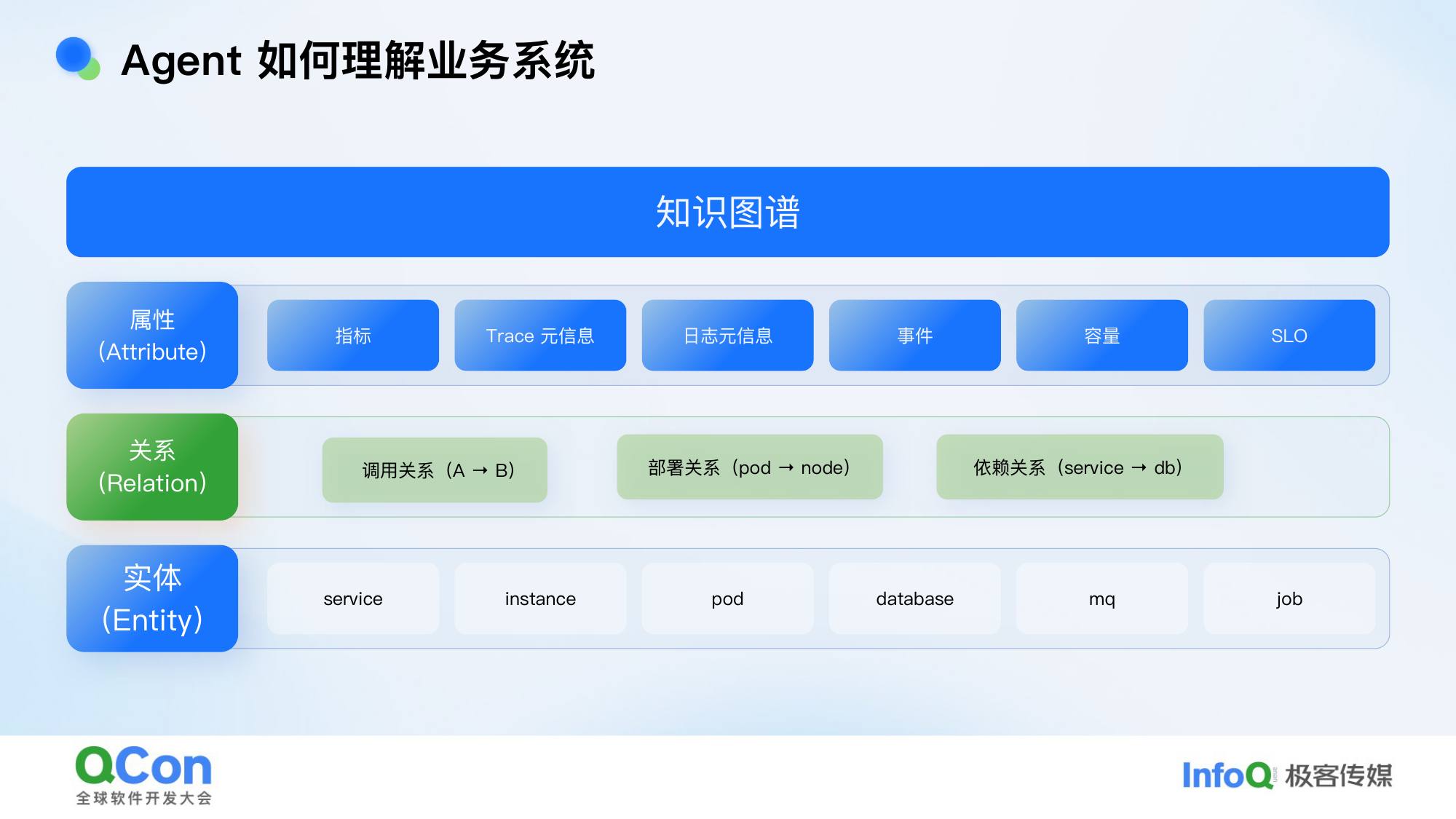
我们把知识图谱分为三层:
- 最底层——实体:监控对象,可以是微服务、K8s Pod、中间件、数据库、Job 等
- 中间层——关系:A 服务依赖 B 服务,C 服务部署在 D 节点上,各种关联关系
- 上层——属性:实体的基础描述(服务名、标签、SLO),以及关联的 trace 元信息、日志元信息、事件信息等
有了这个图谱,就可以通过实体找到它依赖的其他实体,同时对实体做”下钻”——从实体去分析它的日志、traces、事件等。
知识图谱的好处:全局快速查看系统状态;快速收敛分析范围;支持巡检、排查、故障定位。我们最初做这个东西,出发点其实是让人能直观地看到整个系统状态——平台上一看,就知道哪里有异常点、风险点。到了大模型时代,发现它天生适合 AI Agent 做推理。
知识图谱的自动化构建
数据建设才是最脏、最复杂的工作,这一点往往被忽略。大家谈知识图谱应用时,往往假设”我已经有了完整的知识图谱”,但怎么建出来才是关键。
用 AI 加速图谱构建,而不是直接生成图谱数据
核心思路:不让模型直接生成知识图谱数据(成本高、幻觉率随数据量增加),而是让模型生成一套规则,再用规则驱动程序持续更新图谱。
以指标数据为例:一个数据库里可能有几千万、几亿条时序曲线,不可能全塞给模型。但我们只需要做抽样,让模型分析:这条指标叫什么名字、有哪些标签、标签的 key 和 value 是什么,模型就能识别出”这是某个服务的 CPU 曲线,IP 标签对应的是机器实体”。这样就提取出了一套规则——用 IP 标签值作为实体标识。规则生成后,程序定期执行,知识图谱就能持续更新。
日志、traces、事件同理——通过模型自动分析关联关系,不需要人工逐个梳理每个服务的归属。
实际场景中,规则类型很有限,可能就是 MySQL、K8s、物理机等几类,每类生成一套规则,程序来执行。
知识图谱在 AI Agent 中的四种用法
1. Graph as Context(上下文)
把知识图谱作为模型的上下文。典型场景:分析日志异常时,直接把异常日志扔给模型效果不好——模型不知道哪个 error 是真正导致成功率下跌的,哪个只是无关的依赖报错。把知识图谱作为上下文注入,告诉模型当前服务是什么、依赖哪些组件,可以增强模型的背景信息。
2. Graph as Tool(工具)
把知识图谱作为 AI Agent 的工具。典型场景:定位多层次异常,底层某个故障层层传播到上层服务。把图谱作为工具注入后,模型可以自己调用工具查询依赖关系——“A 服务异常,查一下它依赖的 B 和 C 服务”——避免把整个图谱、整个 trace 全塞进上下文,同时约束了推理路径。
3. Graph as Planner(规划器)
把知识图谱作为规划器。在复杂场景下,先让模型做规划(列出 1、2、3、4、5 步),再按步骤执行。知识图谱作为规划器,可以约束分析流程,避免模型看到一个服务就分析一个服务、链路过长导致中间细节丢失。比如强制要求:A 服务异常,必须先看 A 服务的日志和 traces,得到基本洞察,再基于洞察调用工具分析下游路径。
4. Graph as Validator(验证器)
把知识图谱作为假设验证的循环。模型往往过于自信——分析出”根因是 B 服务”,但 B 服务到底有没有问题?需要验证。流程:得出结论 B 后,去知识库查 B 的健康指标、成功率、存活状态。如果 B 确实有问题,结论明确;如果 B 指标正常,告诉模型”B 是正常的,重新思考”;如果 B 根本不在知识库里,无法验证,则提示模型给出不确定的结论。这个机制能有效避免模型的过度自信误导人。

Harness 工程:精准信息供给
Harness 这个概念本质上和”上下文工程”是一回事——给模型提供最精准的信息,信息过多产生幻觉,信息过少模型无法推理。
指标数据的处理
指标有两种输入方式:文本(时间戳+值的序列)或多模态截图。多模态受模型能力限制,效果一般,我们目前还是用文本。
文本方式的问题:一条曲线正常时基本平稳,异常时才有几个异常点,把全量数据塞给模型很浪费,而且对分析没好处。我们的做法:做算法前置处理——异常点检测、趋势分析,只把异常点和整体趋势给模型,信息直接、准确,对定位准确率和上下文消耗都友好。
日志数据的处理
故障时日志会刷屏,一个服务可能瞬间几万条甚至几十万条。全量给模型不现实。我们的做法:
- 日志聚类和去重:用经典的日志聚类算法(如 Drain)提取若干模板,每个模板里抽样,保证关键日志不丢失
- 关键词提取
总体思路:用传统工程和算法手段提升确定性,减少分析耗时和 token 消耗。
多 Agent 协作(解决 Lost in the Middle 问题)
模型上下文有限,而且存在”Lost in the Middle”问题——上下文过多时,中间内容会被遗忘,只记得开头和结尾。
我们的架构:一个 Manager Agent 主导整个故障分析逻辑,生成共享上下文(当前故障背景、异常指标、故障对象在知识图谱中的元信息、业务自定义知识库、skills 等),分发给各专项 Sub-Agent(日志分析、指标分析、事件分析等)。每个 Sub-Agent 在自己领域做分析,结论汇总回 Manager,由 Manager 综合生成最终的故障定位结论。
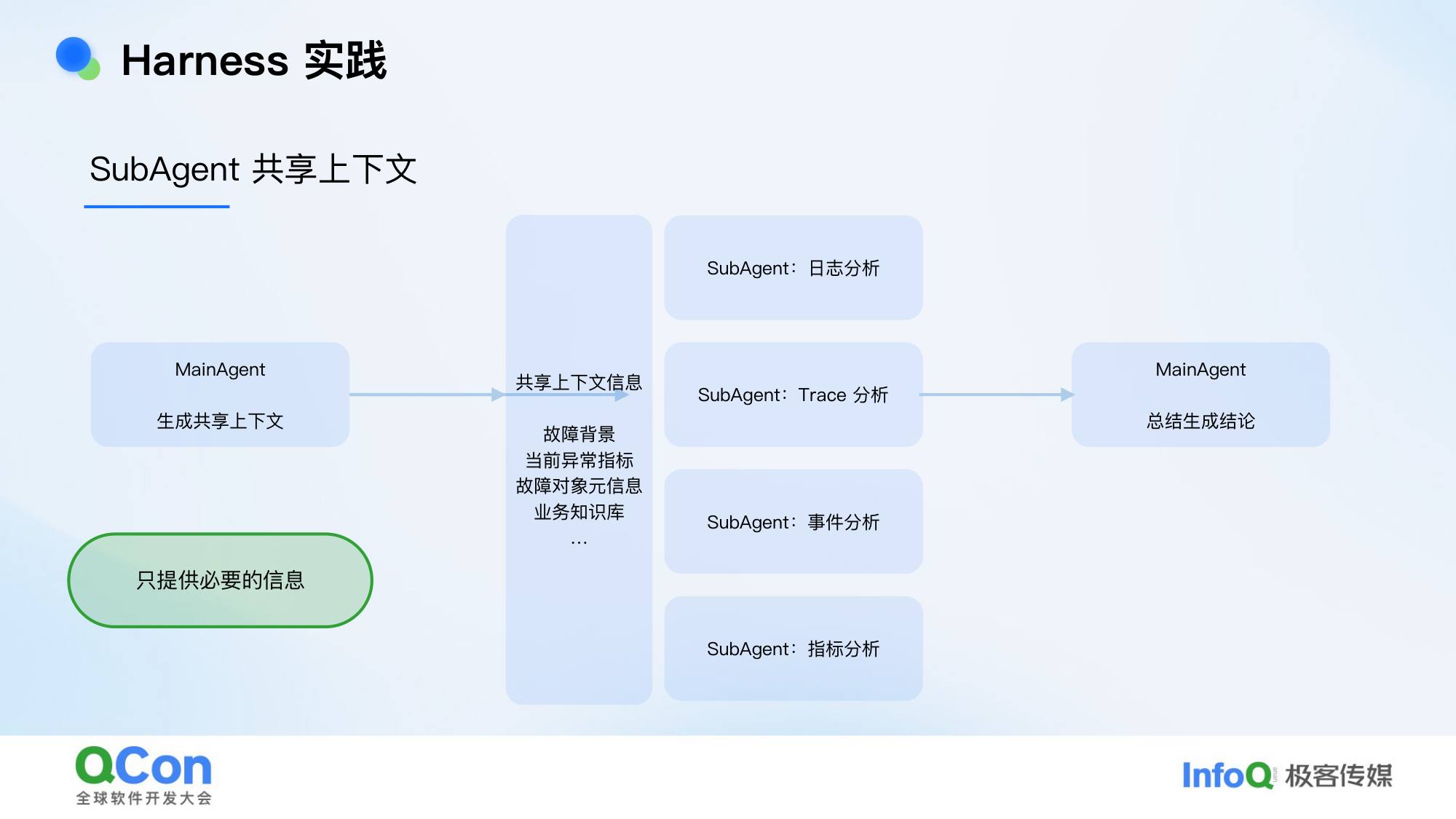
原则:只提供精准且必要的信息。
Workflow vs. Agent
去年大家更倾向于做 workflow 编排——针对某个告警场景编排一个 workflow,不同场景不同 workflow。今年更多转向 Agent 方案——用一个通用 Agent 解决所有问题。
但在我们的实践中,workflow 并没有失去意义:
- Workflow 解决确定性问题:场景明确、能力结构化,workflow 更可靠
- AI Agent 解决不确定性问题:不知道该先分析谁、有长尾问题,交给 Agent 自己决策
实践上,我们会把固定的 workflow 也包进来,后续可以把 workflow 转成 skill 描述给模型,既平衡了 workflow 约束过紧的问题,又给模型一定的确定性流程。
Skill 和 Tool 的设计取舍
关于 skill 设计:用一堆自然语言描述”先调用 A,再调用 B,再调用 C”,效果远不如直接写成脚本、封装成接口让模型调用。确定性逻辑用工程方法实现,比完全依赖自然语言更可靠。
关于 tool 设计:运维类 AI Agent 和通用 Agent 不同,不需要设计各种通用工具,而是基于定制化场景设计。对于危险操作,可以根据场景明确禁止执行。
AI Agent 的记忆系统
在故障定位场景中,记忆分三类:
- 短期记忆:故障现场,包括指标、日志、traces,以及各 Sub-Agent 的结论
- 结构化记忆:知识图谱本身,包括实体关系、下钻路径
- 业务知识和 skill:根据不同业务场景沉淀的知识库,指导 Agent 如何操作
还有一种长期演化记忆:Agent 应该能自我学习。历史故障分析完后,Agent 应该记住结论,下次遇到类似故障可以参考。但这里有复杂机制——一年前的故障经验未必适合今天,需要设计时间衰减和淘汰机制。这个方向我们还在探索中。
产品落地:FlashCat
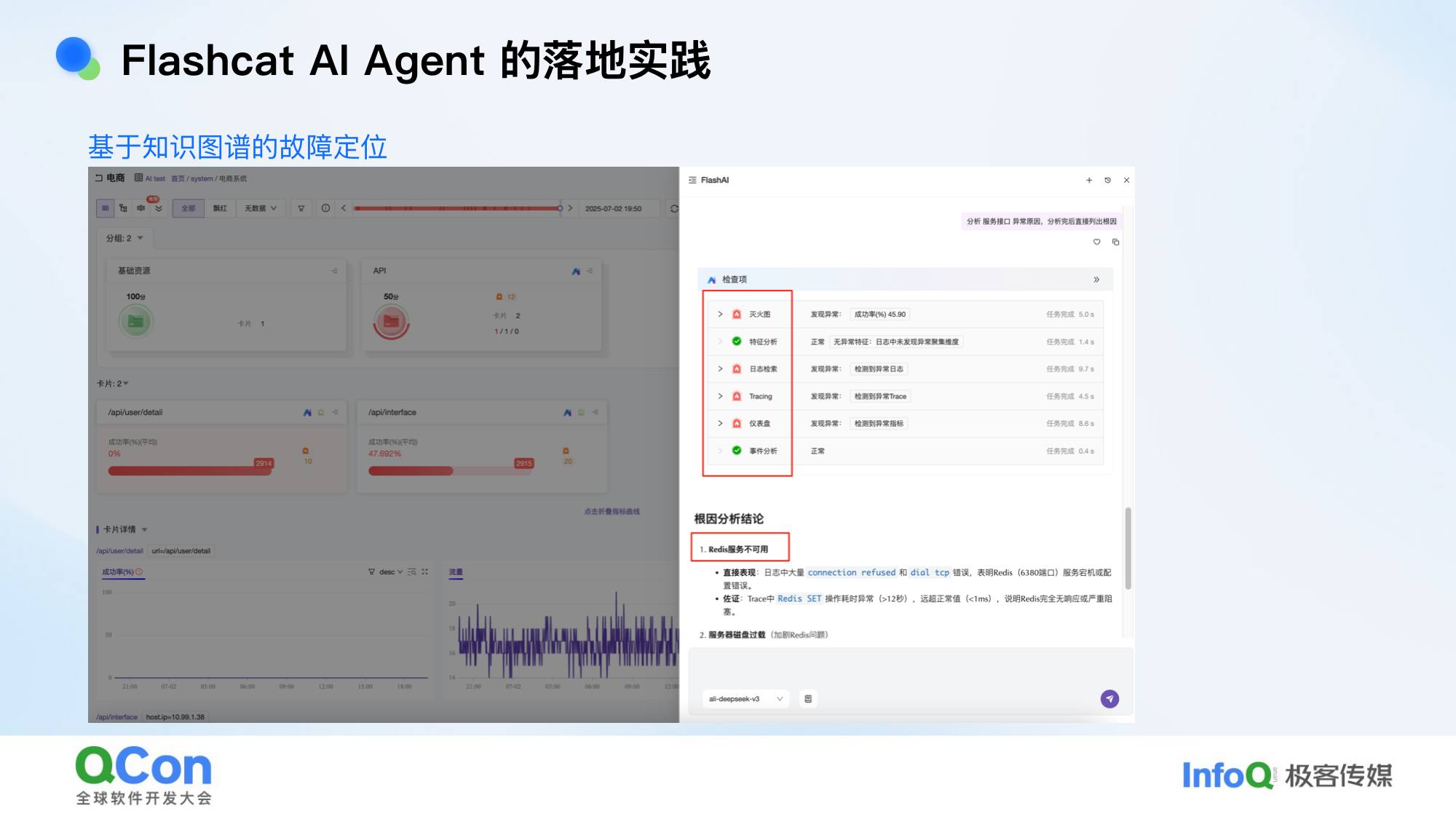
FlashCat 是我们基于开源运营实现的可观测性产品,把上述知识图谱能力做了平台化和可视化。
架构分三层:
- 最底层:数据集成(metrics、traces、logs 等)
- 中间层:灭火图(可视化的知识图谱)
- 最上层:AI Agent 流程,包括标准逻辑、记忆、运行时逻辑
使用流程:
- 接入各种数据源
- 通过自然语言创建知识图谱规则——AI 自动分析数据源,提取实体、创建规则,人工修正即可
- 可视化界面:每个圆圈是一个实体,有异常/正常的可视化展示,可以下钻查看日志、traces、事件
- 自然语言交互触发故障定位:Agent 通过各种模式约束分析路径,依次分析依赖关系,给出结论
- 扩展到日常巡检:让 Agent 巡检整个知识图谱,发现当前有哪些异常
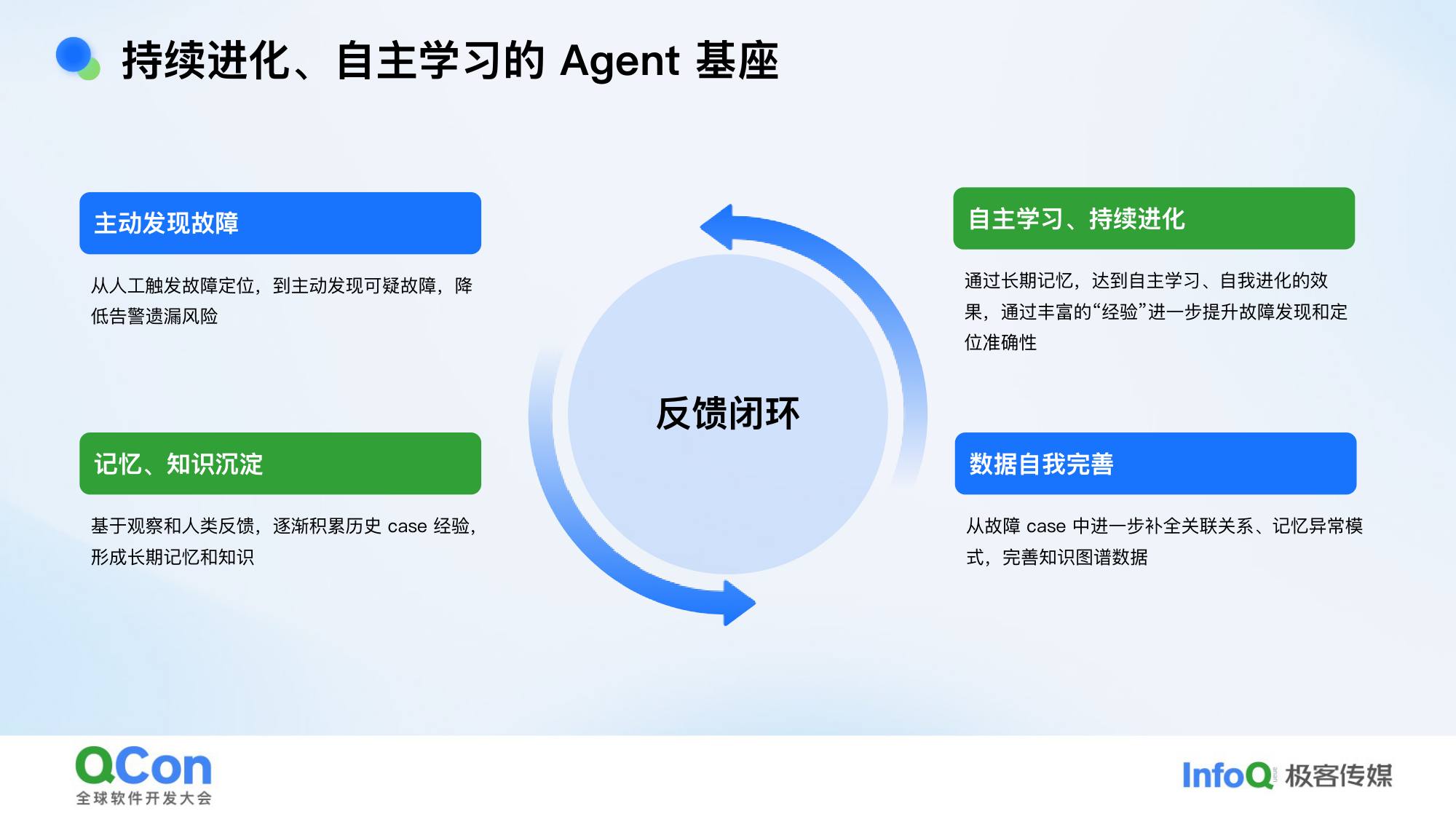
未来展望:AI 生成的代码越来越多,人很难逐行审查,可观测性变得更加重要——通过监控来判断系统是否可用。未来平台应该是能持续进化、自主学习的系统,通过反馈闭环不断优化故障定位能力。
感谢大家。
Q&A
观众(多个问题):故障定位的评估比较难做,你们有做评分机制吗?另外指标特征提取用的是自研算法还是参考业界的?还有知识图谱里的数据会变化,同步机制是怎么做的?
主讲:评估确实是难题。目前我们平台还在公测阶段,还没有完整的自动化评估体系。我们后续会做一些规划,比如跟大促方向结合——代码改动后,知识图谱里的 spec 会随之更新,保证数据的时效性。指标特征提取方面,我们结合了业界算法和自研,不是完全从零做。知识图谱的同步是定期 + 实时双链路,指标/日志/拓扑变更都会触发更新。