QCon 2026·淘宝闪购:可复制的 AI Coding 全栈实战
主讲:邓立山(淘宝闪购,高级技术专家)
时长:约 50 分钟
让 AI 写出可控代码,本质是对软件工程的深刻实践。淘宝闪购分享了从”差那么点意思”到 AI 编码率 89.2% 的完整演进路径:双端约束减少幻觉、工程架构作为”宪法”、AI 自我审查闭环,以及如何把经验复制给整个团队。
开场
大家好,我叫邓立山,来自淘宝闪购,主要负责团队的技术架构、研发效能和安全生产。今天分享的主题是「可复制的 AI Coding 全栈实战」,还有一个副标题——“比 OpenSpec 时代更轻量、更清爽、更丝滑”,不过这个副标题被我吃掉了,因为 AI 发展实在太快了。
今天从五个方面展开:
- AI 编码在生产实战中,为什么总是差那么点意思?
- 我对 AI 编码可控的本质思考
- 整体实战方案,以及如何将经验沉淀为团队资产
- 方案的运营与推广
- 对下一阶段 AI 编码演进的思考
一、生产实战中的痛点
自从 ChatGPT 爆火,尤其是 2024 年上半年 Devin 和 Cursor 出现后,各大媒体开始喧嚣”程序员要失业了”。当时我们也很慌,于是在 2024 年下半年开始探索 AI 编码。但实践下来发现问题很多:
- AI 根本不懂我们的需求,写出来的是代码框架,业务逻辑基本是空白或写错
- 代码位置放错,不符合我们工程的目录结构
- 写了很多,但质量保证是个大问题
那到底是 AI 能力不行,还是我们用的不好?从模型参数、工具(从 Copilot 到 Agent)、资本市场(Cursor 估值一年涨 5 倍)来看,AI 是可以写好代码的。问题出在哪里?我认为有三个原因:
1. AI 工具的天然短板
AI 编码本质上是概率模型,天然有幻觉,但我们的需求是确定的。另外 AI 训练后知识固化,不了解我们的业务需求和工程结构。
2. 人机协同机制缺失
以前写代码用汇编或高级语言,一条语句执行结果可被编译确定。到了 AI 时代,编程语言变成了自然语言——语气和语调不同,表达意思就不同。如何把自然语言转化成 AI 可以确定执行的指令,是个大难题。另外,以前代码质量靠人工保障,AI 时代 AI 编码的质量怎么保障,也是关键问题。
3. 认知固化
推广时发现有些同学觉得 AI 有幻觉不敢放手,还有些担心把编码工作交给 AI 后自己干什么、技能会不会退化,更喜欢做确定性的执行类工作,不愿意真正去思考如何驾驭 AI。
编码范式的演进
从自动补全 → Vibe Coding → SDD 规范编程 → Harness 可控编码,每一步都是在意识到上述问题后的探索。

二、AI 编码可控的本质
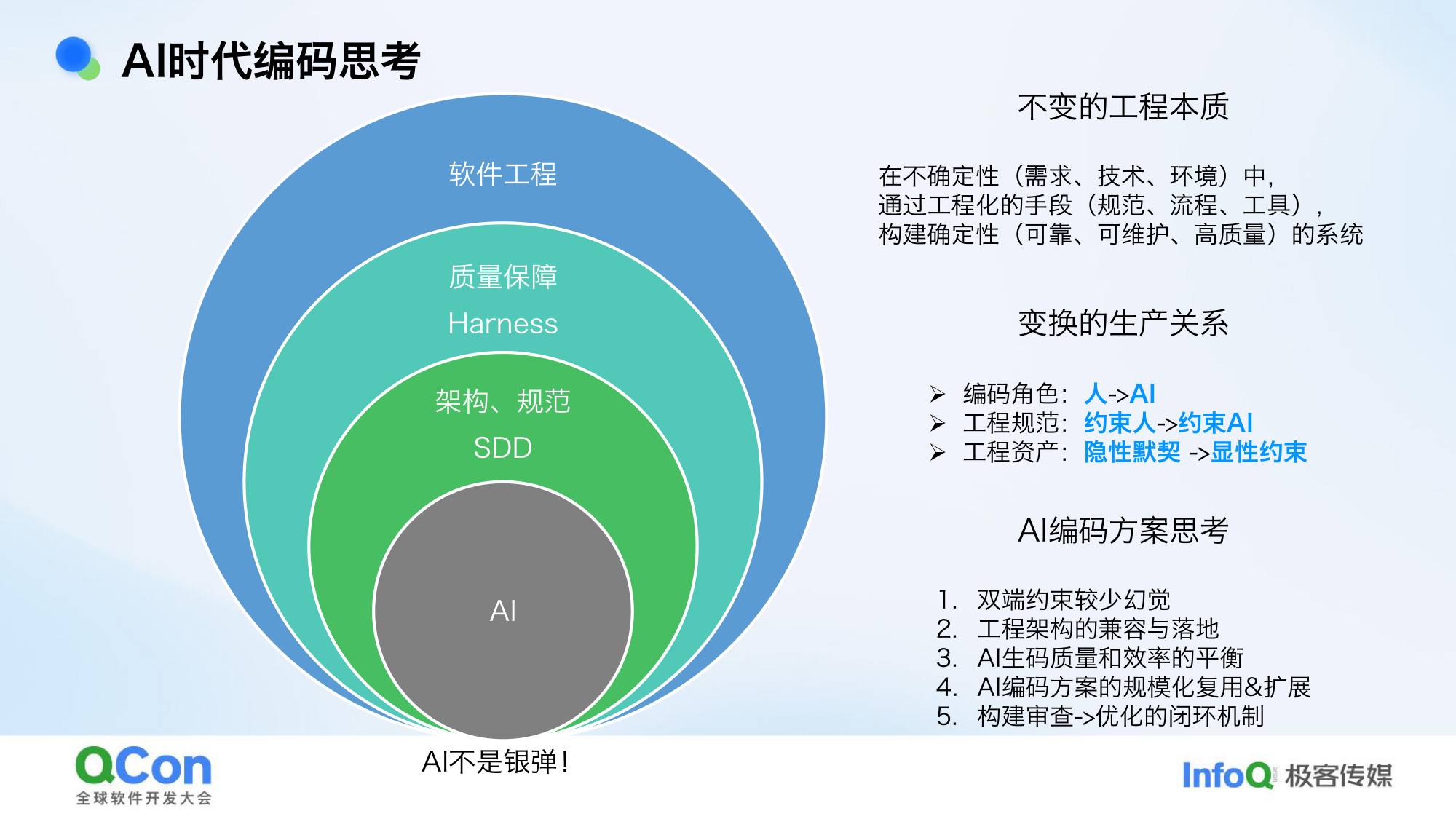
核心观点:让 AI 写出可控代码,本质是对软件工程的深刻实践。
无论是 Harness 还是 SDD,从软件工程角度看都不是新概念,本质都是要交付确定性、可维护的软件。变的是什么?是生产关系:
- 以前:人写代码,架构和规范约束人
- 现在:AI 写代码,架构和规范要约束 AI
- 以前架构规范存在于每个开发者脑海里,AI 并不知道——需要把它显性化,让 AI 能读懂我们的工程
三、实战方案
3.1 减少幻觉:约束输入和输出两端
与大模型交互有三个环节:输入 → 模型思考 → 输出。我们能控制的是两端。
输入侧:把需求描述清楚。针对新增需求和修改需求,定义了不同的规范和模板。需求分析有不清楚的地方,让 AI 集中列出来等人确认,而不是自由发挥猜测。
输出侧:按不同阶段建立不同层次的规范——需求分析阶段遵守什么规范、代码编写遵守什么规范、code review 遵守什么规范。这套模板能清楚描述功能点的前置条件、业务流程、业务规则。
新增需求侧重整体架构设计,修改需求侧重现有代码的变更分析,两套模板分开。
3.2 工程兼容:工程架构作为”宪法”
AI 生成代码和现有工程系统兼容,是最容易被忽略、最容易留下技术债的地方。
解决方案:先让 AI 把整个工程结构描述出来,包括架构模式、目录结构、技术栈、编码风格。这也是个好机会,让我们重新审视架构——随着需求迭代,很多模块职责早已偏离了最初设计。
梳理出来后,把这份工程架构作为宪法注入给 AI,在任何编码时刻都要遵守。实现手段可以用 .cursorrules 或项目级的 CLAUDE.md 等文件。
有了工程架构约束,AI 就不会乱写乱放,会遵守整体结构产出代码。
3.3 编码粒度:项目级一次性生成
把编码粒度分为 7 个等级,从上到下效率越来越高,但质量越来越不可控。随着模型能力增强,可以不断向下探索。
目前我们的实践粒度是单工程项目级——需求只涉及一个工程时,代码可以一次性完整生成。
上下文爆掉的问题:通过任务拆分解决。先让 AI 把需求拆成任务列表,用任务方式记录编码状态,中断后可以方便恢复。实测案例:一个真实线上需求,中间只停了一次,我只说了”继续”,最终一次性生成 66 个文件、5000 多行代码。
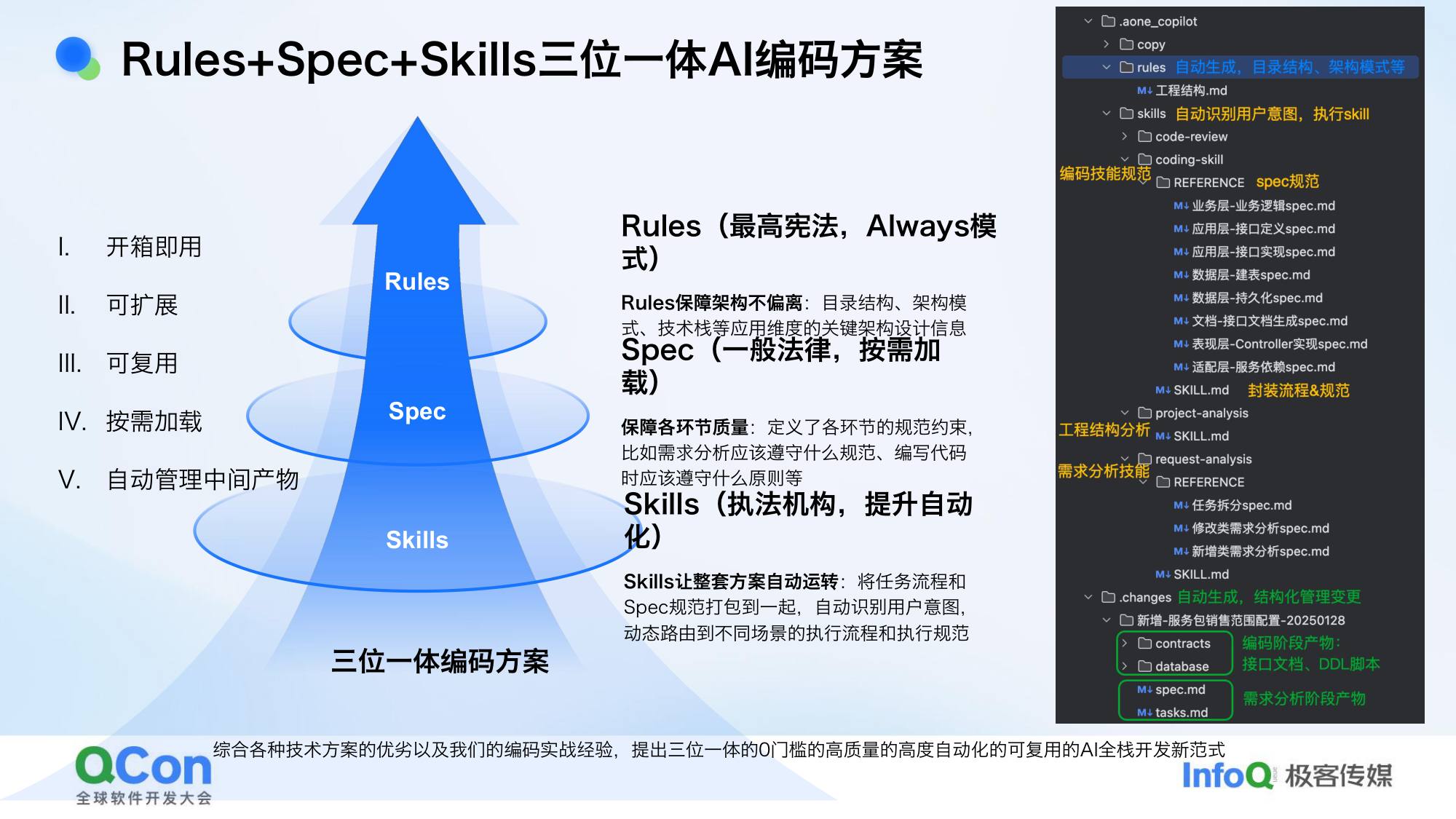
3.4 方案可复用性:解耦业务逻辑与规范
不希望每个人都要重新调试一套编码规范。解决方案:把业务逻辑和规范解耦,规范里不含任何业务逻辑,这样一套规范可以给整个团队复用。
扩展性设计:
- 研发流程组件化:不同研发流程包装成独立的 skill,如需求分析 skill、编码 skill
- 文件化隔离:新增需求和修改需求对应不同的规范文件
- 编码内容结构化:某个流程、某个文件、某个场景有问题,直接增加或修改对应规范
3.5 AI 自我审查闭环
AI 一次性生成成千上万行代码后,质量审查是大问题。我们的做法:AI 自我审查 → AI 自我优化迭代 → 人工最终审查。
AI 自我审查维度:
- 业务逻辑与代码是否一致
- 整体代码设计
- 代码质量
- 代码规范
通过这个机制,迭代 3-5 次基本能生成质量较高的代码。人工只需重点关注 AI 容易忽略的高风险地方(如容易产生资损的逻辑),不用逐行审查。
实测:一次性生成代码后直接让 AI 做 code review,初始评分约 70 分。经过第二轮迭代,严重问题基本解决,达到 96 分。本地编译一次性通过。
四、方案演进历程
这套方案不是一次性成型的,随技术发展不断演进:
2024 年下半年:以 Cursor 为代表的 AI Coding 工具迅速普及,我们开始探索,以质量为优先。
2025 年 2 月:形成第一版方案,通过 Prompt 技术包装,出了技术方案模板,让大家按模板描述业务需求。当时已能一次性生成整个服务所有方法的业务逻辑(如门店管理的增删改查),但规范还是手动选择给到 AI。
2025 年 7-8 月:出现了 Rules(.cursorrules),通过 Rules 方式重新升级方案,增加了 AI 自动生成技术方案的能力,并增加了对修改类需求的支持(前期只做新增需求,担心线上风险)。
2026 年初:发现 Skills 技术很好,可以解决分层规范手动选择的问题。通过 Skills + Rules + 我们自研的 Spark,从研发流程和规范约束两个维度重新构建整套方案,实现开箱即用——用户感觉不到任何规范和 skill 的存在,因为 skill 本来就是大模型根据语义自动识别加载的。这套方案也比较符合 Harness 工程的理念,只是我们聚焦于编码阶段。
为什么没有直接用 OpenSpec?
我们调研了两类主流方案:OpenSpec 和 Spec-K,各有优缺点。OpenSpec 学习成本低、自动化程度高,但缺乏统一的规范机制和需求层级划分。Spec-K 正好相反。
我们尝试了 OpenSpec,深度实践下来问题不少:
- 汉化程度差,生成文件中英文混杂
- 需求拆分时没有分清 requirement 和 scenario,导致编码时业务逻辑实现不完整
- 前后端任务混在一起,但前后端研发关注点差异很大
- 任务拆分不符合我们的研发习惯(我们习惯从底层数据层到上层应用层逐步实现)
- 集成我们的规范后,扩展性差,整个流程反而更重
正确的拆分方式:比如”删除门店”是一个功能点,”成功删除”和”取消删除”是两个用例,而不是把整个需求拆成 6 个 spec 文档分散在不同文件里。
最终方案架构
类比软件架构体系:
- Rules(宪法):工程功能结构、架构模式、技术栈等工程维度信息,时刻约束 AI 不偏离
- Skill 文档(法规):各环节规范——需求分析规范、编码规范、code review 规范
- Skills(执法机构):自动识别当前在做什么、参考什么规范,自动加载执行
- 需求迭代文档(绿色):吸收 Spec-K 的优点,统一管理编码过程中的相关文档,DDL 脚本、接口文档等在编码过程中一次性生成
用户只需把这套方案拷贝到本地工程目录,使用时感觉不到任何规范和 skill 的存在。
五、前端编码实战
前后端研发特点差异很大:
- 前端:从需求拆分页面 → 页面拆分业务组件 → 分析交互逻辑
- 后端:从需求拆分功能模块 → 功能模块拆分功能点 → 细化业务逻辑和业务规则
针对前端特点制定了专门的研发规范,但整体研发流程和后端一致:功能结构分析 → 需求分析 → 编码。
实际需求分三类:
- 有完整 PRD 的需求:给到 AI 后,页面元素和交互逻辑还原度都比较高
- 一句话需求:适合技术驱动的运营提效类场景,AI 能分析设计技术方案,但组件交互逻辑需要人补充
- 接口文档驱动:直接把接口文档给 AI,能还原出对应页面
六、方案运营与推广
把方案变成团队方案并不容易,人的认知很难改变。我们不是强制推广,而是营造编码氛围:
- 技术分享:不定期邀请最佳实践者分享经验
- 月度评审:邀请团队 HR、leader、大部门 leader 来给 AI 编码造势,评选月度”编码先锋”
- 梯度推广:先小范围试点,打磨方案后,在每个团队选一个人带一个需求,一对一指导,做完后他们把经验带回团队做辅导师,形成”分享→实践→沉淀→再分享”的飞轮效应
效果观测:
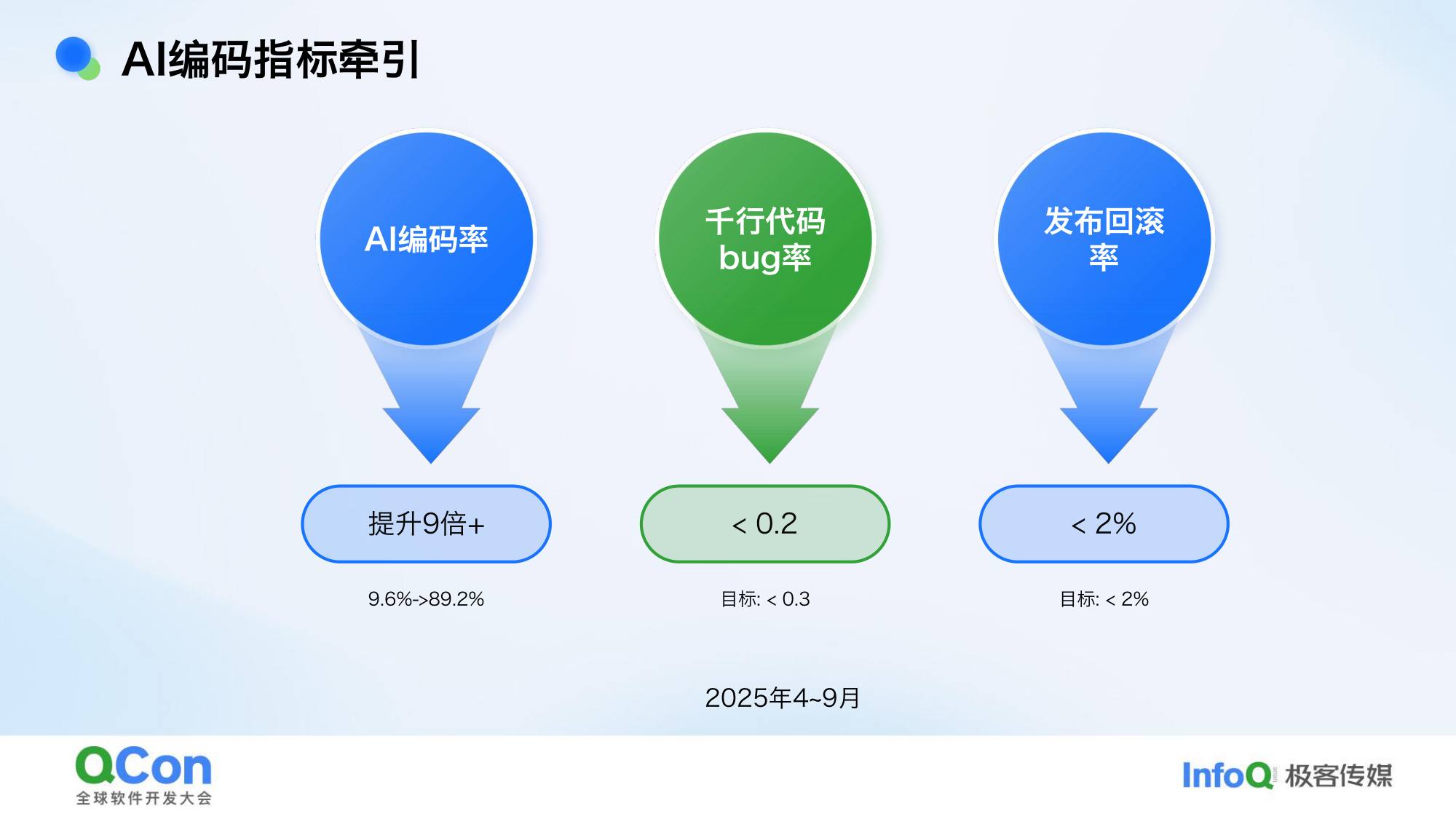
- 指标一:AI 编码率
- 指标二:千行代码 bug 率和发布故障率(质量不能变差)
从 2025 年 4 月推广到 9 月,AI 编码率从 9% 提升到 89.2%,实现 9 倍以上提升,整体代码质量符合预期。
对外产出:24 篇 ATA(蚂蚁技术社区)文章,其中 8 篇获翰林院推荐(翰林院是 ATA 最高荣誉,全平台整体推荐率约 1/20,本团队获推荐率远超平均),12 篇上头条(全平台约 1/12)。对外公开文章获得 10 万+ 阅读量、1 万+ 点赞转发收藏。
七、未来演进与思考
回顾过去三年:智能补全 → Vibe Coding → SDD 规范编程 → Harness 可控编码,人的参与度在减少,AI 自主化程度在不断提升。
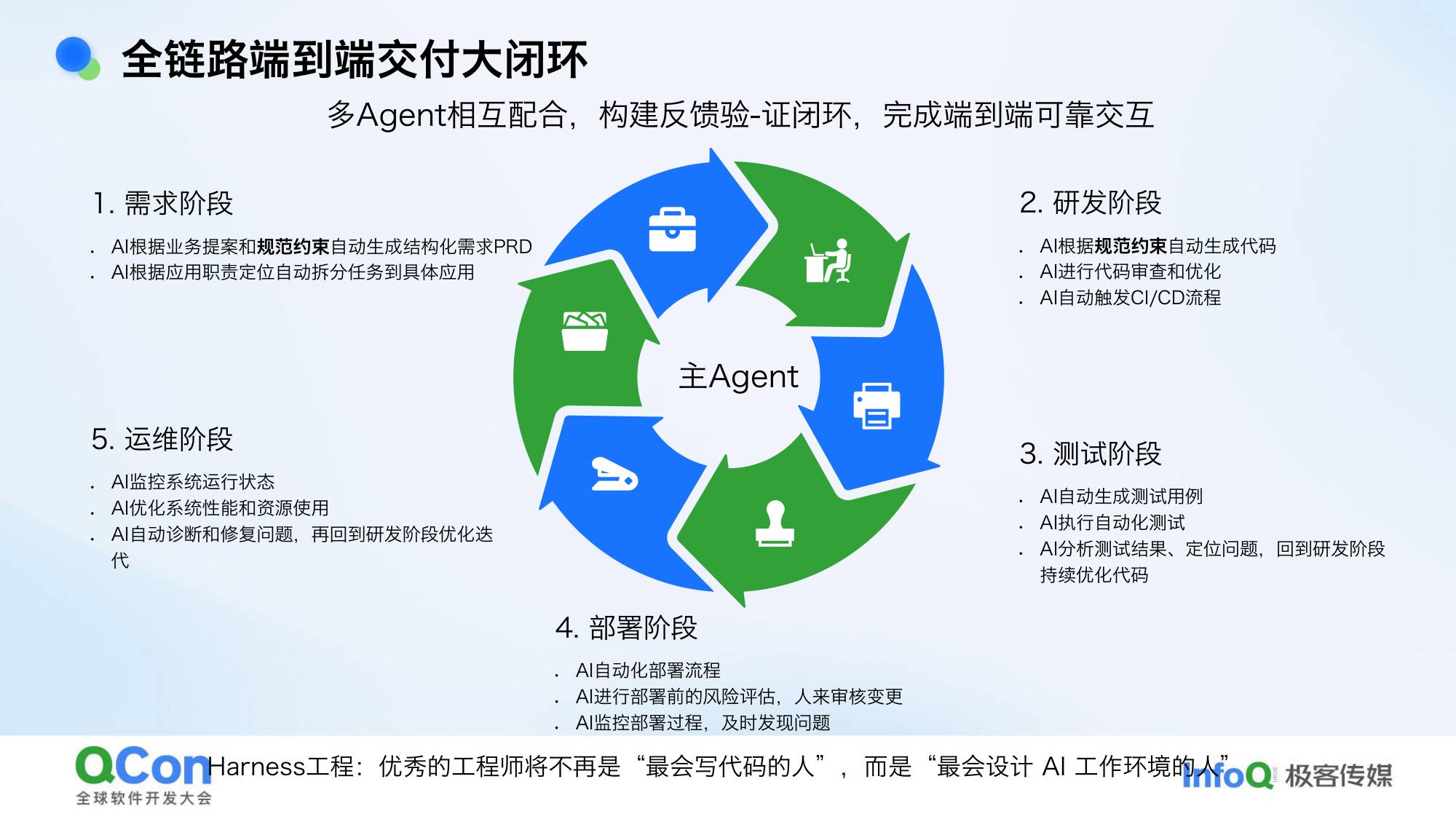
下一阶段:从研发阶段到整个研发周期,构建端到端交付闭环。内部有两个小循环:
- 研发阶段:编码优化 → CR → 单测
- 测试阶段:自动化测试 → 测试报告 → 回到编码迭代
大循环:从需求阶段到线上运营阶段全链路打通。
程序员角色转变:
- 从代码执行者 → 规范制定者 + 决策者 + 质量守门员
- 从关注模块细节设计和写代码 → 关注战略设计和 AI 运营环境设计
- 从”代码即规范”→”规范即代码”,未来可能不再看代码,重点是设计和迭代规范
- 从”我比 AI 强”的认知 → 如何高效与 AI 协作
结语:AI 不是银弹,但它是超级杠杆。用好这个杠杆,不只是把提示词写好,而是需要更清晰的工程思维、更严谨的规范意识、更深刻的软件工程哲学。AI 编码,本质上就是对软件工程的一次深度实践。