QCon 2026·蚂蚁:Vibe Coding 平台落地半年后的实践经验
主讲:彭佩乔(蚂蚁集团支付宝体验技术部,前端工程师,花名乔洋)
主持:臧志(百度,Coding Agent 驱动的研发新范式专场出品人)
时长:约 56 分钟
蚂蚁内部 Vibe Coding 平台(代号 Muse)落地半年、月活过万的真实踩坑记录。从 search & replace 到 KV Cache 的 token 优化路径,到”文件即记忆”和”一切用 git 管理”的架构理念,再到五个关于 AI 时代基建的”暴论”。
平台介绍
我们在去年(2025 年)7 月左右在蚂蚁内部做了一款在线可视化的 Vibe Coding 平台(内部名 Muse),到现在已经有大半年实践时间,踩了很多真实的坑,今天来分享。
平台定位:用自然语言和 AI 对话生成前后端全栈网站,面向内部所有员工,不需要任何技术背景,会打字会敲回车就行(最近还加了语音输入,连打字都不用了)。
支持四种网站类型:
- 静态前端网站:简单场景,不多说
- 前端 + 内部接口:蚂蚁内部有统一 API 网关,所有服务端接口自动注册。用户选中想用的接口,平台自动把接口元信息封装成大模型易理解的上下文,让大模型完成网站。适合有自己服务端的场景
- 全栈应用(最大量):非技术用户不懂技术但需要做存数据的真实服务。用户只需自然语言对话,平台自动生成表结构、关联关系、CRUD 接口,连上前端
- 内嵌 AI 助手:在第三种基础上,给网站加一个 AI 助手,用户可以在网站上和 AI 对话完成功能。大模型调用、流式渲染、定时任务、工作流节点等都内置好了
使用体验:支持一边对话一边实时预览浏览器渲染效果;支持直接选中文字修改排版颜色(兼容低代码用户习惯);支持多人协作和预览链接分享。
数据:做了半年,内部月活已过万,其中一半是非技术群体。平均对话 12 次左右可以完成一个完整网站。
Case 1:PMO 同事——Token 成本优化
背景
一个 PMO 同事找我,要做数字化管理平台。第一个月账单 5000 多块,花了很多钱。用户没有错,钱是平台的问题,我得想怎么省钱。
Token 主要花在代码逻辑上。当时的做法:把 2000 行代码文件整个扔给大模型改,一来一回 4000 行,太贵了。
精准修改的演进
方案一:git patch 格式
让大模型生成 patch,成功率只有 80%——patch 格式复杂,一旦出错轻则改错,重则崩溃,而且错了还看不出来。不可接受。
方案二:行号定位
告诉模型改第几行,成功率从 80% 提到 90%,还是不行。2000 行的文件,模型会记错行号,而且改错了也没报错,更可怕。
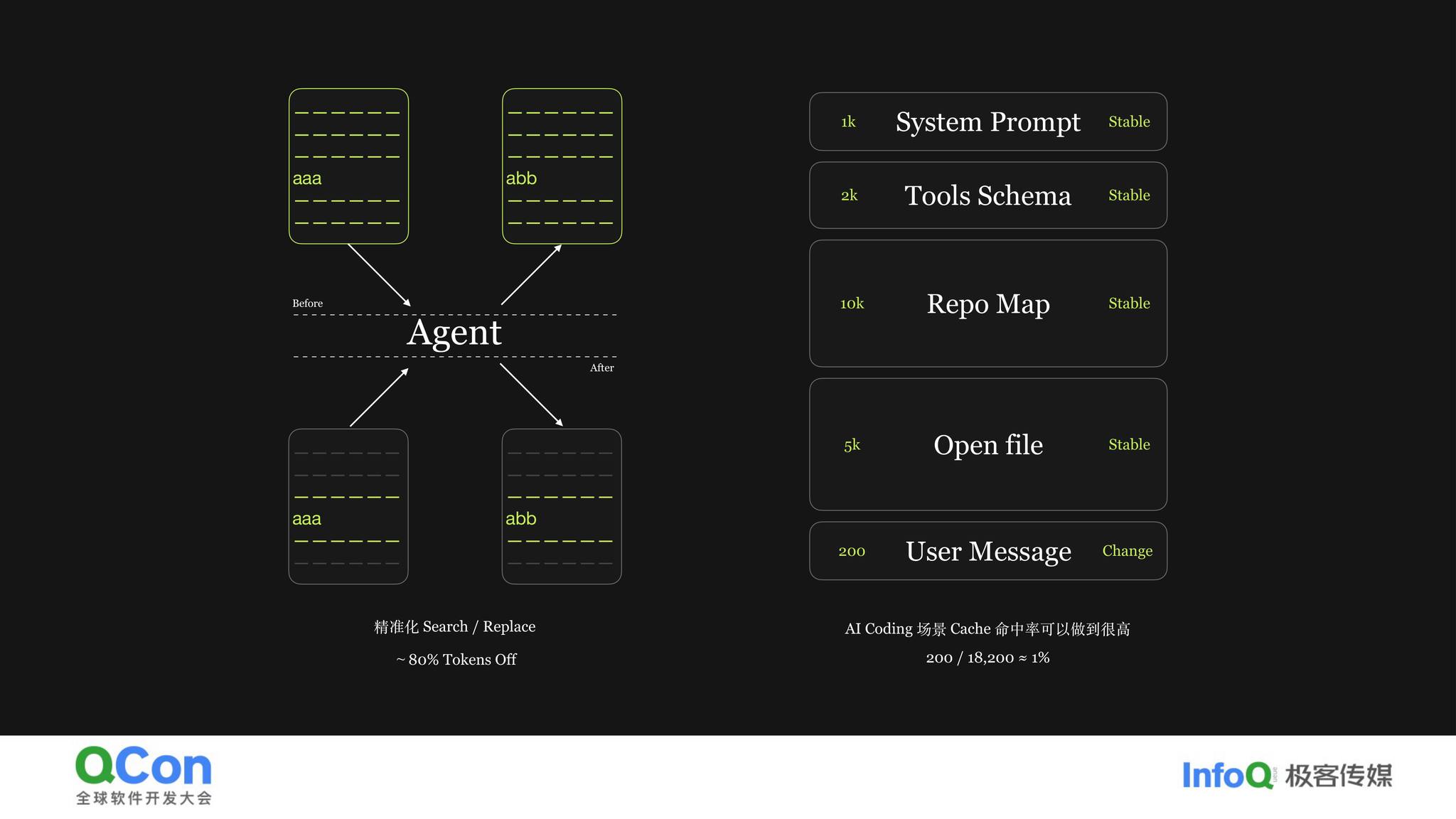
方案三:search & replace(现在通用方案)
把原始内容和新内容都给我,我自己去 search 再 replace。工程化优化:如果目标字符串出现多次,让模型多给一行上下文,narrow 到只有一个匹配时才应用 patch。这个方案成功率接近 100%。
KV Cache:更根本的省钱方案
这些 token 小技巧,最近发现其实可以被 KV Cache 方案覆盖掉。
KV Cache 原理:大模型 GPU 推理的计算结果可以缓存在显存里复用。KV 前缀不变的部分不用重新计算。比如 Anthropic 的 Claude,支持 5 分钟或 1 小时两种缓存模式,命中后打一折,非常便宜。
怎么用:在 Coding 场景天然适合。把不变的部分固化:
- System Prompt:不放任何动态内容,不插时间戳,人设固定不变
- Tools 列表:固化 10 个左右的工具(read、write、replace、create 等),序列化方式保持稳定,保证 KV 前缀不变
- Repo Map:代码仓库索引(有哪些文件、依赖是什么、README),项目没有大重构就不会变,也是 stable 的
这样过半的 token 就已经不变了,这部分打一折。真正会变的只有用户的 user message。实测真实场景缓存命中率约 80%,已经非常便宜了。
顺带一提:最近有个热门项目把自然语言压缩成信息密度极高的类文言文形式来省 token,这类小技巧以后可能都会被 KV Cache 方案覆盖。
这个 Case 的三点启发
不要用固定 workflow 限制 AI:有段时间产品喜欢搞”先分析→前端 Agent→测试 Agent”这种流水线,不要搞。AI 能力越来越强,固定 workflow 只会让效果变差。Harness 才是正确理念:给 AI 真实世界的工具和反馈,让他自己决定怎么做,自己优化。
文件即记忆:受 Manus 团队启发,每一个重要的执行结果都持久化成文件存在目录里,只把索引放到上下文里。需要时让大模型自己用文件方式读取。为什么?文件是 Linux 的一等公民,也是大模型的原生语言——bash、cat、grep 这些它最擅长,给文件地址它自己会 search、head,能精准找到想要的内容,不会把上下文压死。Skills 也一样,以文件形式存在目录里,保持稳定可召回。
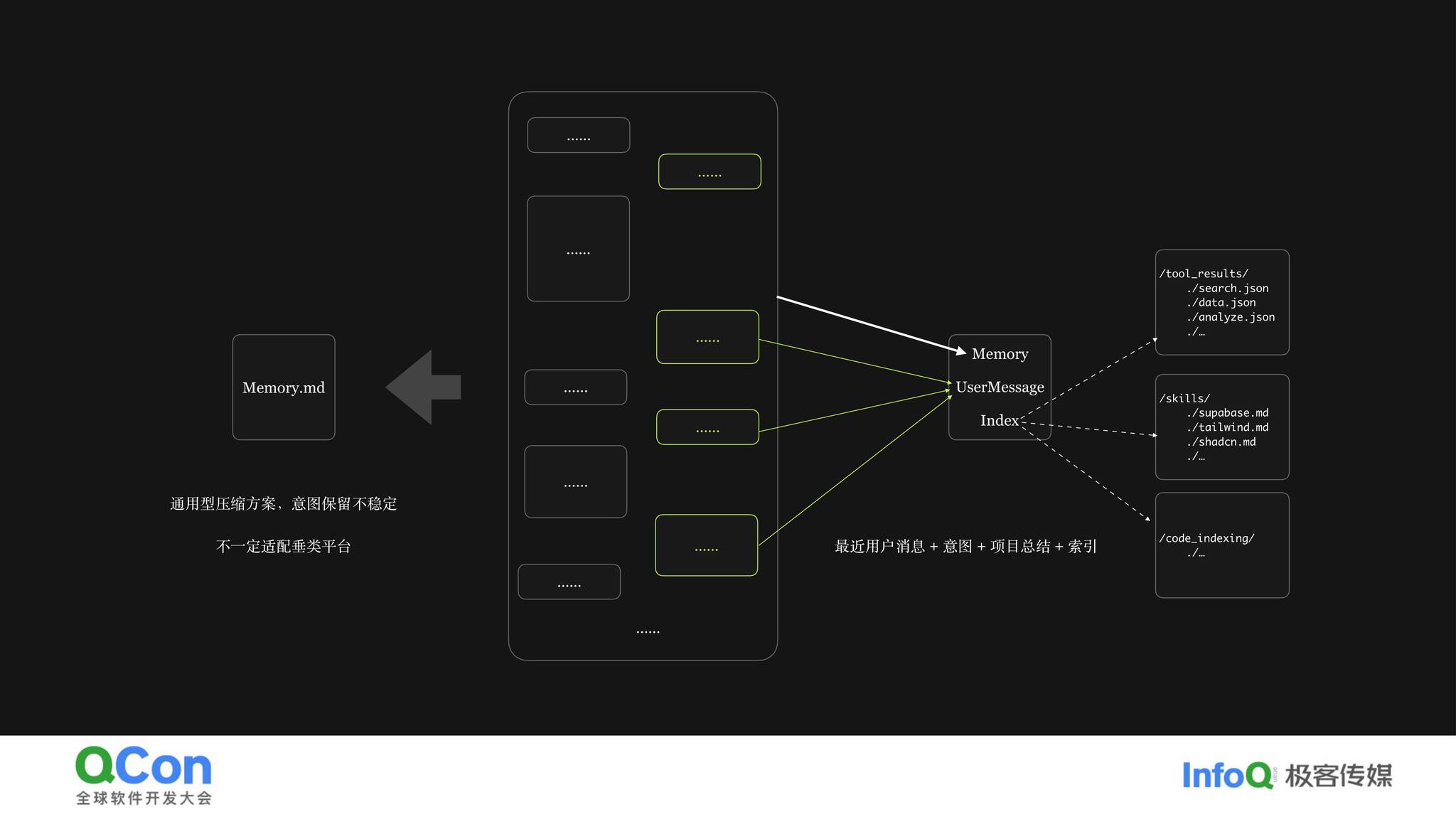
- 超大工程管理:传统工程基建在 AI 时代依然有用。比如提前对项目做一次编译,构建有向无环图描述函数定义和引用关系,给 AI 一个查询工具,它就能精准找到函数在哪定义、被谁消费,直接操作,效率远高于让 AI 自己搜索。把工具提供给 AI,让 AI 决定怎么用。另外 context 一定要管好,1 兆上下文也会 lost in the middle,注意力依然会发散。

Case 2:HR 团队——企业私有知识落地
问题
HR 说平台 AI 太笨,听不懂”阿里价值观”这类内部概念。大模型没训练过,没办法。
解法:Skill 中心 + CLI 对齐
正好那段时间 CLI 化理念兴起,我们借助这个思路在平台做了内置支持:让 HR 口述内部知识库语料,转成 Skill 的形式。建立 Skill 中心,每次遗忘某个 Skill 时,以文件形式存在项目本地,整个 AI 生命周期都能记住。
关键原则:基建一定要和业界标准对齐。 我们整个平台能跑 Claude Code,就是因为标准对齐了,天然享受生态红利。
内置 API 和组件库
HR 要做员工搜索器,不能每次都要求用户手动启动某个 Skill。解法:在脚手架里直接内置 API 和组件库,让 AI 自己决定什么时候启动。这比 Skill 的加载率高很多,几乎 100% 触发。在我们平台说”做一个员工选择器”,直接就出来了,UI 还可以随时修改。
数据安全问题
HR 问:你能看到我的数据吗?我作为平台超管当然能看到,她说那我不用。
解法:测试数据库和正式数据库分开,上线正式数据库后单独设计”数据库管理员”角色,与开发管理权限分离。这类问题在企业内部落地时都会遇到,提前准备好。
内部生态打通
HR 还要求和内部文档、钉钉通知、邮件、日程打通。企业内部平台落地的核心:一定要做一站式全包,连接内部所有生态且合规。 否则用户为什么不用外部平台?合规拦不住的,要真的把用户的工作流搬到你的平台上来。
Case 3:营销同学——C 端大流量 + 私有知识
设计稿还原
营销同学要做蚂蚁森林活动页,有设计稿,要精准还原。以前我们有一套 D2C 方案,把设计稿转 DSL 再生成 React。现在不需要了——多模态模型直接看截图就能还原,让 AI 根据浏览器截图反馈循环修改,简单搞定。
支付宝特有能力的私有知识
支付宝客户端有很多特有 API(比如唤起摄像头),AI 不懂怎么办?
Skill 方案不够完整。更好的方案:在脚手架里内置 examples 目录,把典型用法的例子放进去,并在关键地方放索引指向 llms.txt 格式的文档(AI 友好的文档格式,可直接消费)。例子对大模型来说是最好的学习材料,渐进式披露——它可以直接按照你的模式改代码,也可以去查例子,还可以沉淀到本地复用。
高并发
营销活动需要承受大流量,这逼着我们把平台能力延伸到外部 C 端。我把它叫做”AI 时代的敏捷迭代”:写得快、发得快、跑得好——但肯定还挂得快,这解决不了。
题外话:AI 能帮程序员背故障吗?能帮财务坐牢吗?干不了。高级程序员的价值只会更高,因为只有他们知道怎么更好地驾驭越来越强的大模型。
我们的质量保障手段:
- 每次生成代码自动跑 lint + build,有问题直接在 Agent loop 里反馈修复
- 收集所有 runtime 报错,提供”一键修复”按钮,告诉 AI 哪个页面哪个按钮在什么状态下报了什么错
- 离线扫描:每天定时把每个页面点一遍、每个功能用一遍,报错了让 AI 在用户睡觉时修好
多 Agent 协同与多人协作的挑战
随着用户规模增长,遇到了两个大挑战:
挑战一:跨 Agent 信息传递损失大
用文本在 Agent 之间传递信息损失非常高——把意图压缩成一段文本,丢失了太多。不如直接换角色效率高。
挑战二:多人协同
5 个人一起做一个项目,又要做图片、文档、网站,没法实时多人协同。传统的 git 分支合并方式非技术用户根本用不了。
三个架构理念
1. 一切内容都是文件
文件是 Linux 的一等公民,也是 AI 的一等公民。把图片、Excel、PPT、文档全部转成文件,AI 就可以跨仓库操作所有类型的内容。
2. 一切文件都用 git 管理
以前每种内容有自己的数据库,割裂严重。统一用 git 管理,大模型最擅长 git 命令——想找某个功能为什么消失了,大模型自己去 git log 里找;合并冲突了,大模型自己去排查。而且支持任意版本回滚,不用区分是回滚文档还是回滚代码还是回滚数据库。
3. 一切会话都在 worktree 里
传统 git 分支方式太慢。Claude Code 的作者在开发 Claude Code 时,本地起了非常多 Agent 实例,为了让它们在不同目录里独立工作又能汇总,大量使用了 git worktree。这是现在新的协作模式。

几个”暴论”
1. 未来基建必须天生 AI 友好
以后基建不是给人用的,是给 AI 用的。造轮子的时代彻底结束了——你造一个新框架,AI 不会写,谁会用?要保证你的编程界面和外界开源方案对齐。我们数据库方案完全对齐 Supabase SDK,告诉 AI “这是 Supabase”,它就能直接写,只是换了个底层服务。

2. 文档是写给 AI 看的
你们上次自己读 API 文档是什么时候?现在都是把文档扔给 Claude 让它写代码。所以所有基础能力都必须 CLI 化,必须有一份 AI 友好的文档(llms.txt 格式)。
3. 分清楚你是流量入口还是工具
如果不是流量入口,GUI 不重要,重要的是怎么让你的能力被别的 Agent 调用。未来每个网站都要维护好自己的 llms.txt,设计一套给 Agent 颁发身份的授权系统。蚂蚁内部已经落地了专门针对 AI 的 SSO 系统——之前我把个人 cookie 写到本地让 AI 定时更新,被安全团队找了,因为一个身份每天启动几十个平台太可疑了。
4. 未来所有不能被 AI 驱动的软件都会被淘汰
微软最近在 GitHub Trending 上有个项目,把 Office 系列(PPT、Excel、Word)都转成 Markdown——因为 Markdown 才是 AI 时代的原生第一语言。今年还有个很火的开源项目 anything-to-cli,帮你的软件快速 CLI 化。
5. 交付才是核心,Coding 是最不值钱的事
真正的核心是让用户把工作流搬到你的平台上来,把需求解决。程序员每天真正写代码的时间可能不到两小时,剩下都是开会、扯皮、调试、跨平台部署。
个人演进路径回顾
最早用 Vibe Coding 是为了释放大模型潜力,但发现拉不住他;然后流行 OpenSpec,给他加约束,短期内不好用;然后做 TDD,生成一套测试来约束结果;现在最流行的是 Harness——没有一个固定范式是最好的,核心是在真实环境让 AI 能验证、反馈、修复、循环,持续运行。
近期值得关注的项目:
HermesAgent:和 Claude Code 的区别是,每次完成复杂任务后会自己决定是否沉淀一个 Skill,每次调用 Skill 时会判断是否过时,每 10 次执行后会决定是否提炼思考——自动化的自我进化思路
Karpathy 的理念:人类只写
PROGRAM.md设定目标,AI 自己决定每 5 分钟一次迭代,指标上升了就继续,指标下降了就 revert——纯自动化的自学习循环LLM Wiki:知识管理工具。他们提出把文件直接链接起来变成图的理念
如何用好 Claude Code:最近 CLAUDE.md 的 star 数涨得很快,排名第一。核心启发:释放 AI 潜力和约束 AI 行为是双轨并行的——一边要释放让他做得更好,一边要约束让他按预期来
Q&A
观众:Harness 现在有很多不同定义,你们的理解和落地经验是什么?
彭佩乔:我们有个团队直接改名叫”Harness 工程团队”。Harness 不是一个固定范式,和 TDD、SDD 都不一样。最近大家的共识是:模型 + Harness = Agent。
具体来说:给模型真实的运行环境和工具——跑在云沙箱上,有 Python、bash 命令;它想完成一个任务,可以直接调 Agent bash 判断代码是否跑起来,可以自己截图看 UI 还原得好不好,自己获取反馈,把事情推进完。核心就是:在真实环境让 AI 能验证、反馈、修复、循环,持续运行。
观众:低代码/无代码平台,用户不会 debug,你们怎么保证产出的东西能跑起来?
彭佩乔:去年 7 月刚上线时,首次页面渲染成功率只有 80%,非常难搞。
我们做了两条路:
- 前端跑起来后自动收集 build 报错,反馈给 AI 进入下一循环修复,把首次渲染成功率做到了 99%(努力了约 3 个月)
- 今年切换到 Claude 后,在代码生成节点结束后直接在 Agent loop 里做 lint + test,保证出来的代码已经是好的
观众:产品经理在 AI 时代的角色是什么?
彭佩乔:我们现在已经没有 PRD 评审,也没有设计交互评审,产品经理的交互评审直接是 demo——想做什么功能,直接给工单做个 demo 出来。
但产品经理这个岗位的核心价值更清晰了:AI 时代最懂用户的那个人。他知道用户到底要什么功能,引领非技术群体关心什么,决定产品下一步怎么优化。这个是 AI 替代不了的。