QCon 2026·百度:构建 Coding Agent 的飞轮——Feedback Loop、Benchmark、Agent Engineers
主讲:牛万鹏(百度文心快码 Comate,研发经理)
主持:臧志(百度,Coding Agent 驱动的研发新范式专场出品人)
时长:约 53 分钟
Agent 框架的”感冒”,就是没跟上模型变化。百度 Comate 分享了如何通过 Feedback Loop(MCP 渐进式加载、智能上下文压缩、Tool 执行网络)、场景化 Benchmark(四象限异常值分析)和全员 Agent Engineers 转型,构建一个能持续适配模型演进的飞轮。
开场
刚才那位老师讲了个很好的观点——做 AI Agent 时不要做面向专业工程师的,要做泛人群的。我就是那个”大冤种”,专门做面向专业开发者的那个。
我是来自百度文心快码(Comate)的牛万鹏,今天稍微有点感冒,大家见谅。
来的路上突然有个思路:最近北京天气变化太厉害,我因为没及时增减衣物感冒了。这周 Claude 发了一个新模型,再往前倒几周,各种模型、各种工具层出不穷。我这个应用如果不能适配模型的变化,就跟我感冒一样——Agent 框架的”感冒”,就是没跟上模型变化。
今天分享的核心:构建 Coding Agent 时,如何有效适配模型变化、构建一个能持续运转的飞轮。三个方向:Feedback Loop、Benchmark、Agent Engineers。
一、百度内部 Coding Agent 的使用现状
核心指标:人均每周 query 数
我们选择用 query 数而不是 token 数来衡量,因为 query 更能映射用户真正完成了多少任务——一个 query 代表一个任务。token 数很难说明到底给谁提了多少效。
数据:这周我们一个人一周发了将近 100 次 query,挺多的。
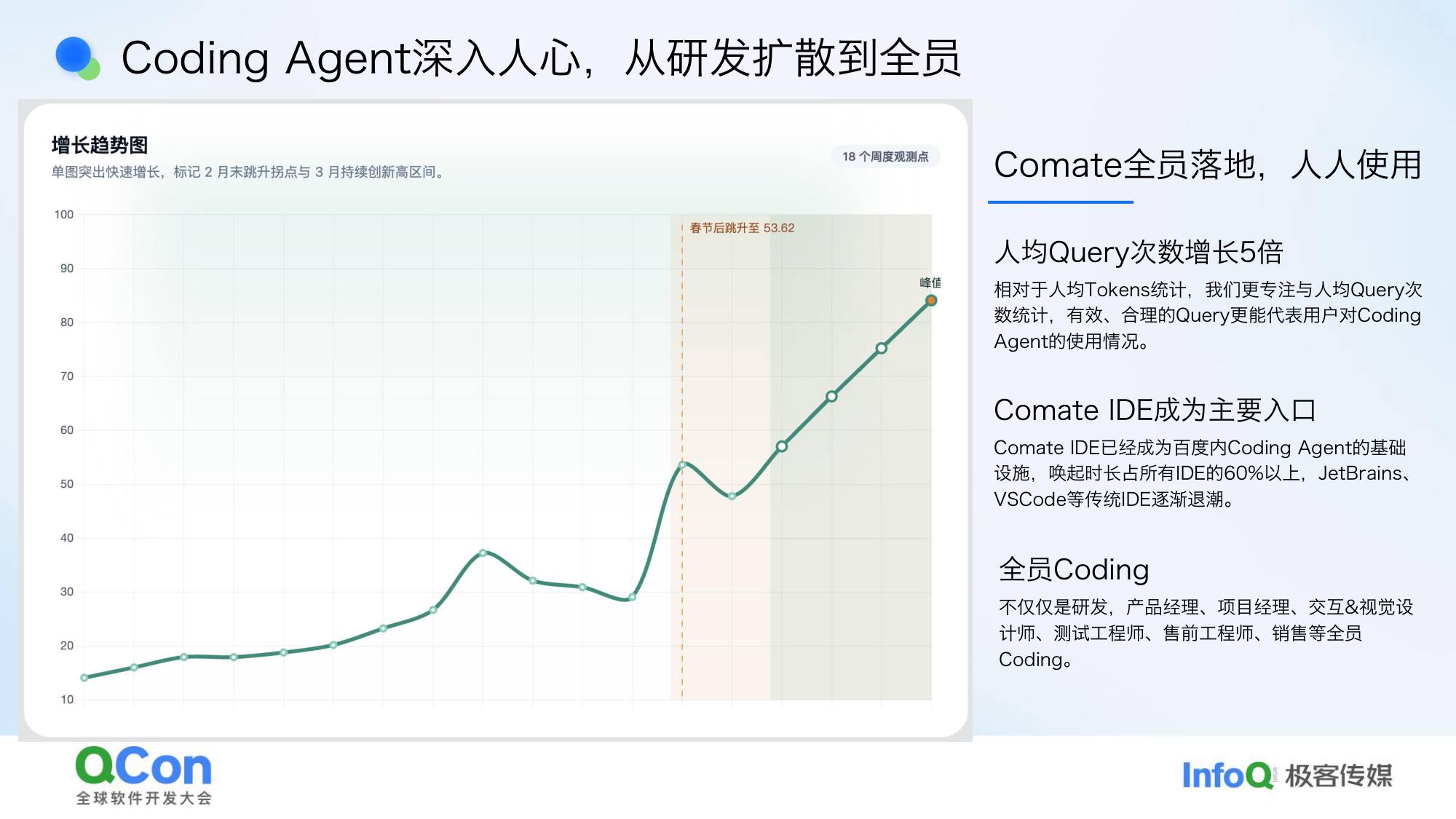
三个值得关注的变化:
1. 工具迁移:越来越多的同学从 JetBrains、VS Code 等传统 IDE 迁移到 Cursor 这类 AI 原生编辑器,不再担心编译调试等问题,都在 IDE 里完成了。
2. 角色扩展:我们做的是面向专业开发者的工具,但越来越多非开发者也在用——售前、销售在用 Comate 做项目管理。这完全出乎意料。
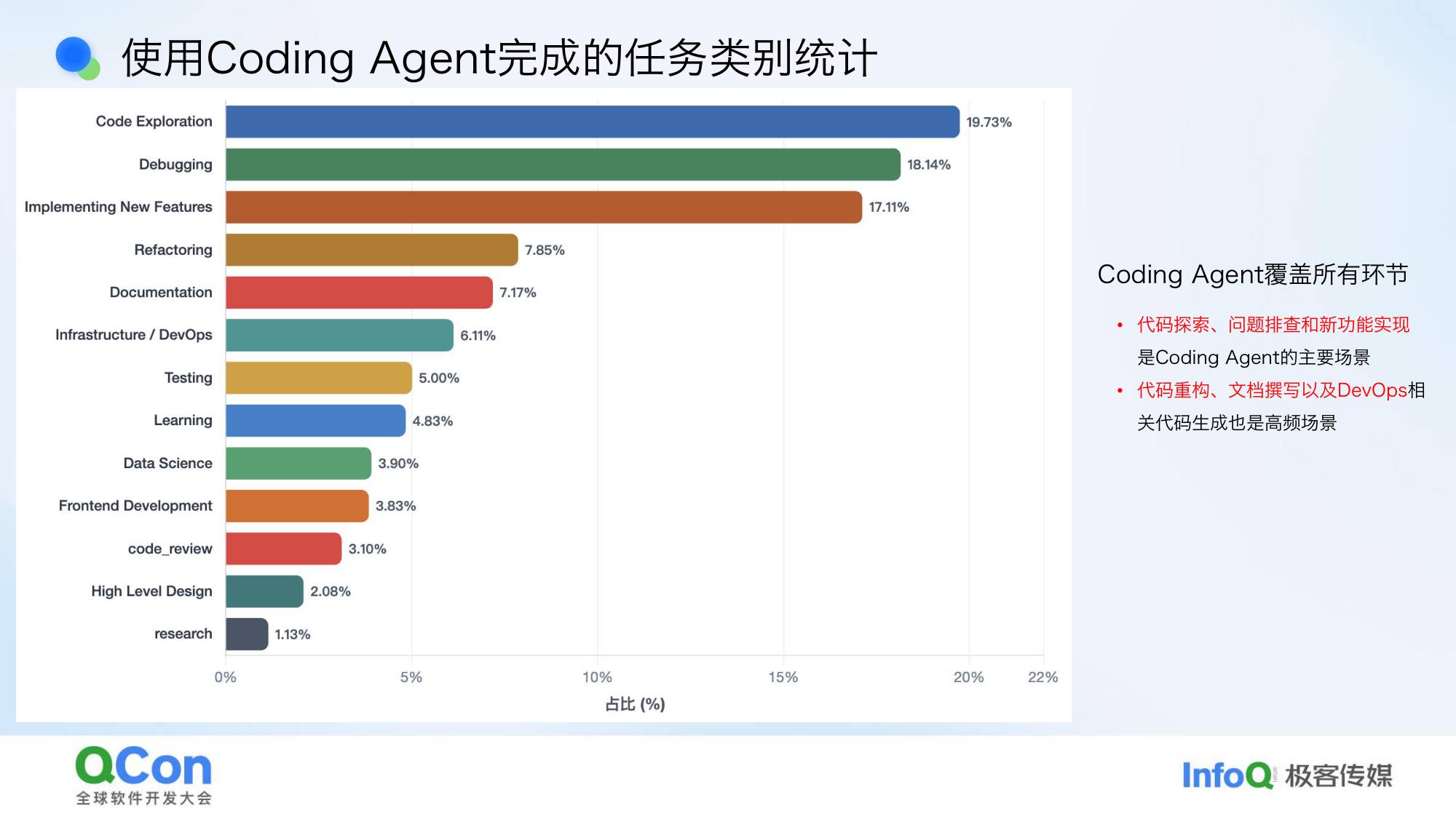
3. Query 类型分布(百度一周真实数据):
最大的三类:
- 代码探索(19.73%):代码检索、代码解释、探索代码库、调研——大量的人在用 AI 获取信息
- 排查错误(Bug Fix):把问题给 AI 让它排查
- 实现新功能(17.1%):才排第三
这恰恰符合工程师的真实工作——我们每天并不都在实现新功能,更多是在研究和排查问题。
两类 query 的业务价值:
第一类:解决之前大量可以用研发解决、但不会被纳入排期的工作。典型例子:产品经理想看过去一周的日活留存,以前要找研发写 SQL,现在产品经理自己用 AI 搞定。这类工作就像战场上的无人机——传统方式调炮兵要层层审批,等决策链走完,人已经走了;现在可以直接精准打击。
第二类:严肃的日常研发迭代。三个月前我还觉得 Agent 只能做一些简单类型,现在已经在大量用 AI 生成代码了。
全栈的重新定义:百度在推全栈,但不是”语言不重要了、你可以写 Python 也可以写 JavaScript”那种全栈。我们的全栈是集各种角色于一身——既有产品经理的 sense,又有交互视觉的 sense,还有构建测试边界的 sense。全栈推动下,大任务交给一个人加 AI,比多人分工效率更高、质量更好。
二、Agent 框架的设计
基本闭环:模型 + 工具 + 环境,构成最基本的 Agent 闭环框架。外围就是 Harness——给 Agent 更多的手和脚去探索外部环境:文件系统、MCP、上下文压缩等各种边界条件。
前段时间 Claude Code 源码泄露,大家可以看到里面有大量处理边界条件的 if-else——所谓 Harness,本质就是把脏活累活、各种边界条件处理好。
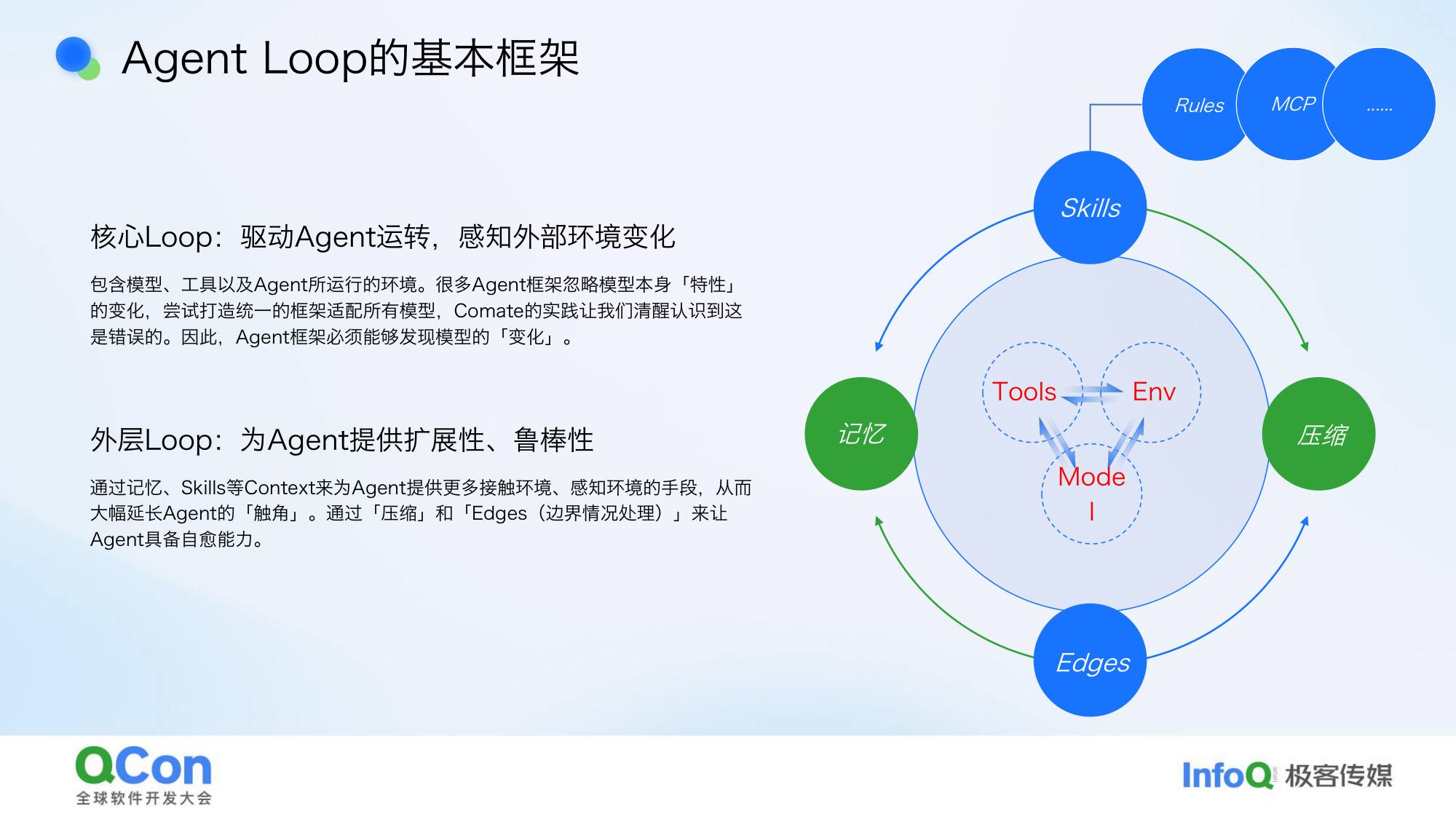
框架为什么会”感冒”:
举个具体例子:DeepSeek 刚出来时,它对 function calling 支持很差,但支持 XML 格式。当时很多社区的 Agent 框架都选择了 XML 路线。但到了去年下半年,DeepSeek 的 function calling 支持已经很好了,原来那套框架就跟不上了。
随着模型能力越来越强,很多之前需要精细处理的细节不再需要了——比如以前要把大任务拆成很多小 task,现在直接把整件事给 AI,让它自己做计划执行就行了。没有一个框架可以永远确定,必须动态强化。
三、Feedback Loop:让 Agent 行为可观测
线上数据:统计什么?
我们认为应该统计 4 个层次的指标(从简单到复杂):
第一层:工具调用
- 工具调用次数、失败率、失败后重试比例
第二层:上下文
- Skill 唤醒情况、上下文消耗
第三层:执行结果
- 一个有意思的发现:当 Agent 创建文件后,反复多次调用工具去修改它,说明第一次创建时分析得不够好。可以通过这种执行轨迹的异常来反推问题所在。
第四层:完整 query 轨迹(最难)
- 从 query 提出到任务完成,整个执行轨迹的质量评估——还在建设中,真的很难。
关键原则:所有数据都要按模型分层看。 以 Claude 为标杆,同时跑其他模型,对比完成同类任务的 query 数和 token 消耗比,发现异常就知道差在哪里。
线上发现的两个具体实践
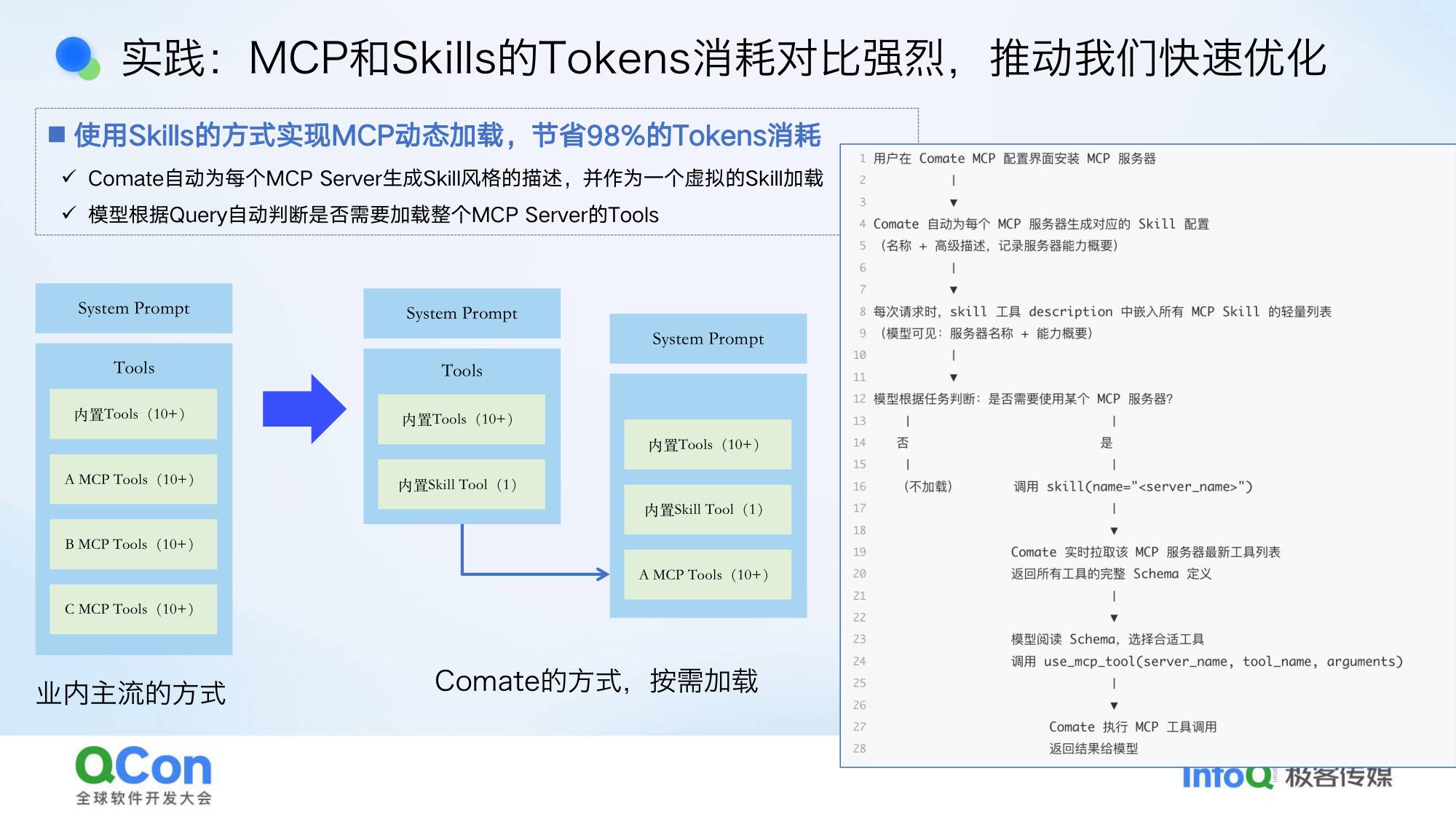
实践一:MCP 的渐进式加载
我们发现 Skill 上下文消耗和 MCP 消耗对比差异非常大。问题是:如果装了很多 MCP(比如 3 个 MCP,每个有 10 个工具),一次性把所有 MCP 工具描述全加载进上下文,会把上下文撑爆。
Skill 和 MCP 不是非此即彼的,各有长处。我们的做法:让 Comate 自动为每个 MCP 生成一个 Skill 描述,内置一个 skill 工具,描述里说明”现在有 3 个 MCP”。当 Agent 真正需要用某个 MCP 时,再调这个 skill 工具,此时才把对应 MCP 的工具加载进来——典型的渐进式加载。这个方案可以节省最高 98% 的上下文消耗。
实践二:智能上下文压缩
我们发现 8% 的工具调用是无效的——Agent 走了错误路径,但它有自愈能力,能捞回来。
问题:传统压缩方式是把整个上下文交给模型做摘要(summary),但这会让缓存失效,造成大量上下文重新计算。
我们的做法:让模型基于当前 query,识别过去哪些工具调用结果已经没用了,直接把无用的部分摘除,而不是整体压缩。这样既复用了缓存,又保障了当前 query 的上下文质量,还能兼顾成本和效果。
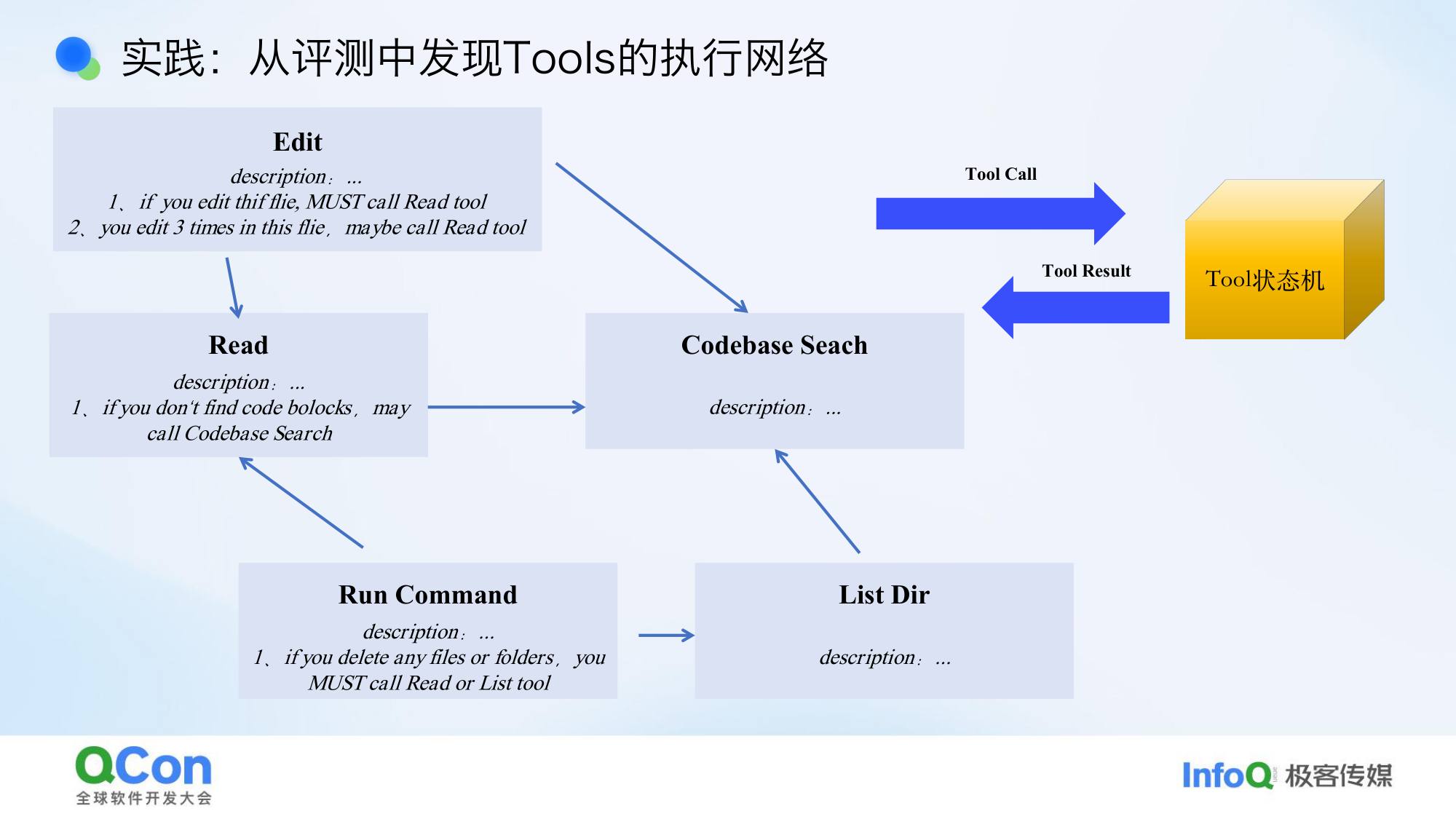
线上发现的另一个实践:Tool 执行网络
通过观察执行轨迹,我们发现工具调用有固定的成对出现模式:
- 编辑文件失败 → 读文件 → 再编辑
- 读文件失败 → ls 查看目录 → 再读
这些是 Agent 自愈能力的体现。我们把这种模式提炼成 Tool 执行网络——工具之间互相指引,形成类似指针的网络关系。
具体实现:给 tool 加 description,比如”如果你从未读过一个文件就想编辑它,应该先调 read 工具”;”如果反复 read 还找不到想要的内容,尝试 search”。
这种方式比强制规定”写文件时必须用 old_string/new_string 格式”更好——不是硬约束,而是引导 Agent 自然地走向正确路径。
四、Benchmark:评测比生成更难
如何构建评测集
从业务本身挖掘:从 git 提交记录里挖。每天都在提交,经过人工审核的合并提交,把这些全捞出来,让 AI Agent 分析 diff log,提取有效的评测 case,最后人工检验有效性。
为什么不用通用 Benchmark:通用 Benchmark(如 SWE-bench)和真实研发场景差距很大。我们需要贴近生产环境的场景化评测。
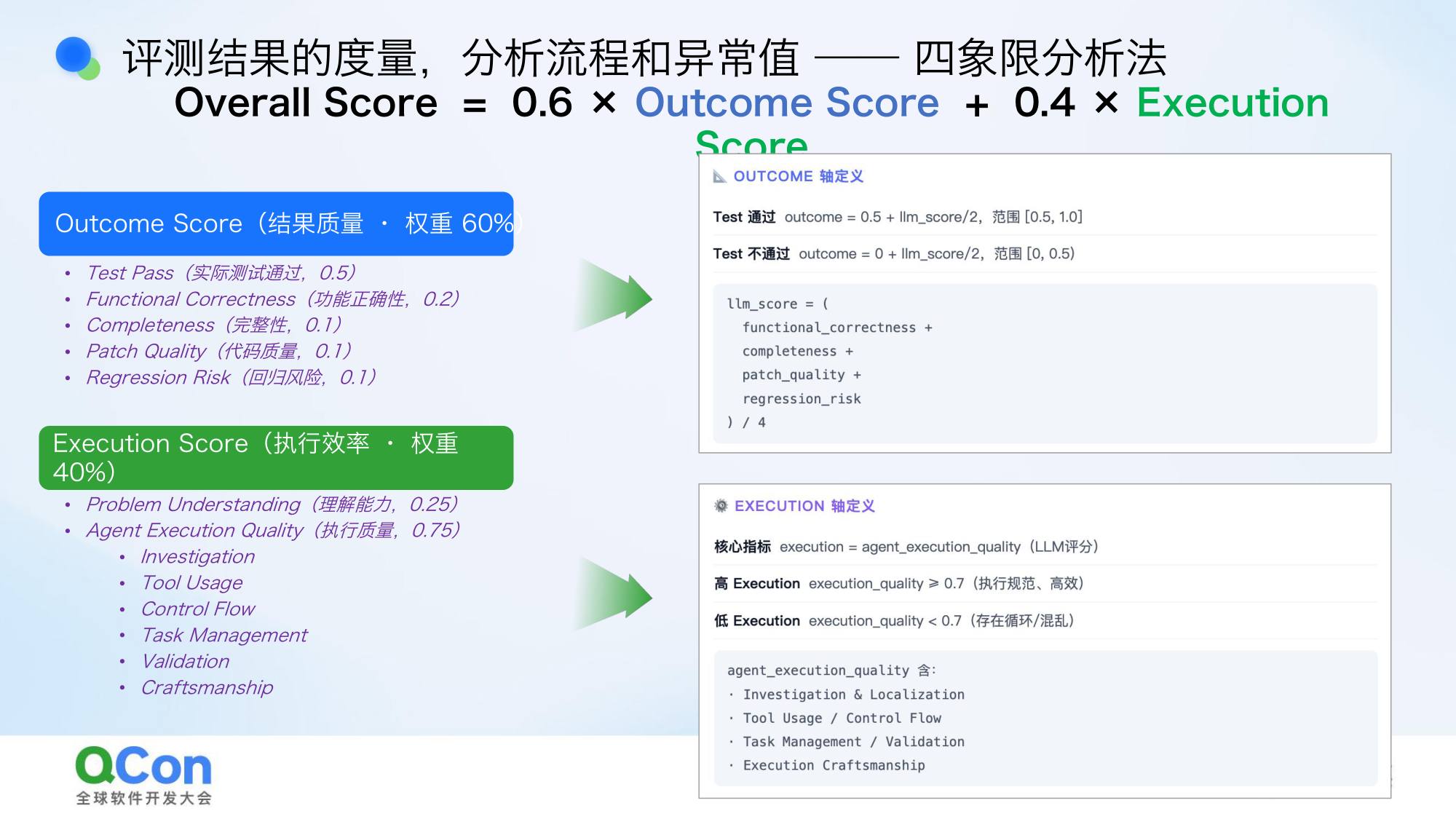
两个核心评测参数
Outcome:度量结果质量
Executions:度量执行效率
用 AI 评判 AI 的问题:让 AI Agent 跑评测,再让另一个 AI 评判结果,是不是左脚踩右脚?
实践发现:用一个干净上下文的 AI 去评判另一个 AI 的执行结果,效果很好。它能给出很多客观的东西,不用担心它帮我们解决不了问题——它可以客观地评判。这也意味着,现在用 AI Agent 做代码 review 也不是问题了。
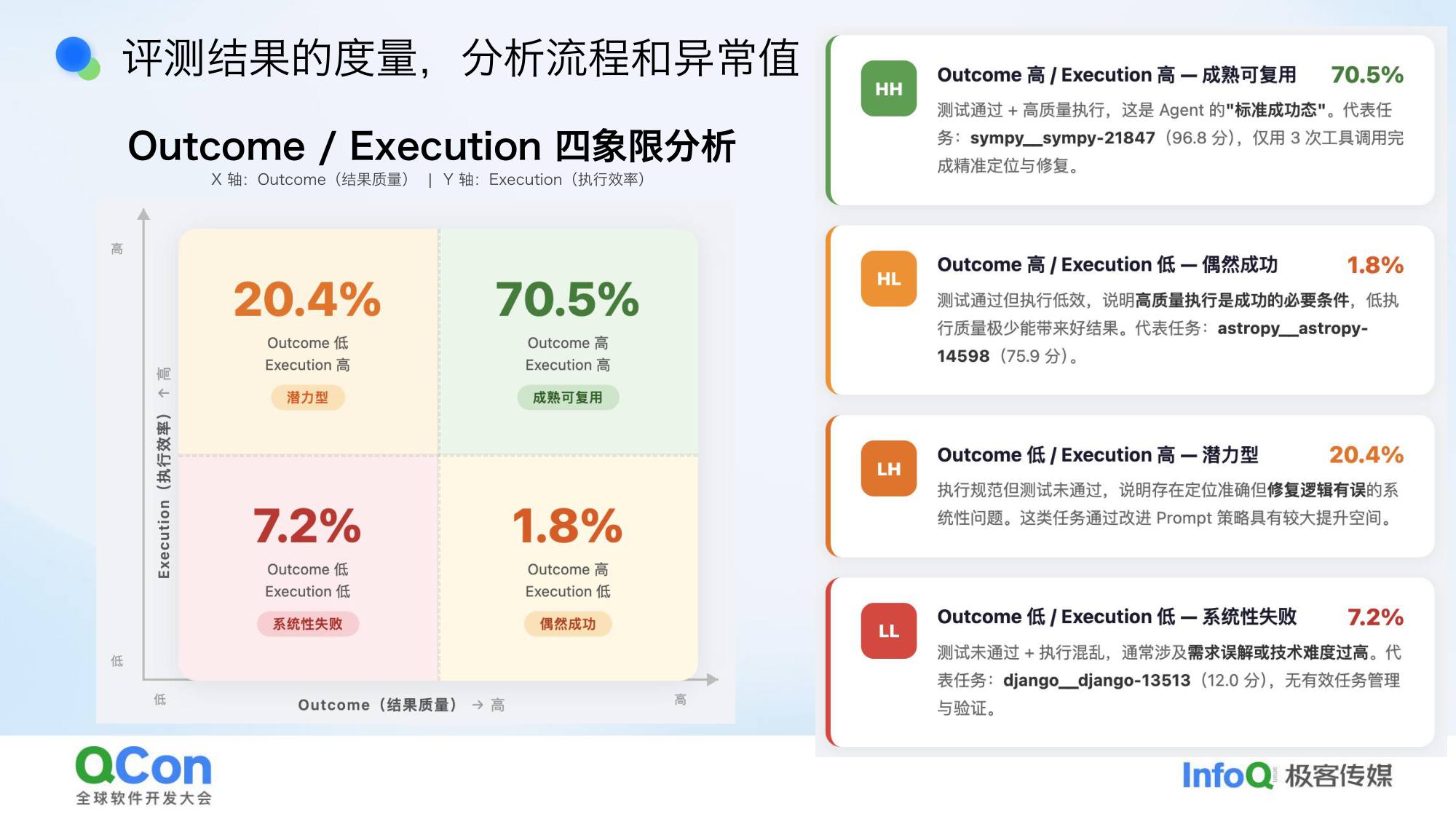
四象限分析:看异常值而非分数
把 Outcome 和 Executions 两个参数组合,拆成四象限:
- 高结果 + 高效率:正常,不用管
- 低结果 + 低效率:明显有问题,调整
- 高结果 + 低效率:异常!结果这么好,执行效率为什么这么低?值得深究
- 低结果 + 高效率:异常!结果这么差,执行效率为什么这么高?说明这类模型倾向于不做自我验证就快速结束
核心原则:不看分数高低,看异常值。 同样 60 分,上次对的题和这次对的题可能完全不同——分数一样,但能力分布变了,只有看异常值才能发现这种变化。
五、Agent Engineers:人如何进入飞轮
两层含义:
第一层:全员转型
推动团队全员转型为 Agent Engineers。不写代码的人很难感知 AI 的变化,所以所有人都要上去用。同时,把人也当成给 AI 的反馈——人看 AI 的输出,就是在给 AI 提供信号。
当前最替代不了的是:产品决策、视觉业务判断、用户 sense、测试品味。
第二层:打破角色边界
具体做法:
- 打破前后端边界:除非极复杂的场景,否则尽可能让 AI 来做,不再区分前后端
- 反转协作链条:以前是产品经理想到点子 → 研发实现;现在是研发先做出 demo,再让产品经理、视觉工程师来评判调整
- 需求原子化:希望 PM 和视觉把自己的 sense 做成 Skill,放进仓库。这件事很难,把人的 sense 做成 Skill 真的不容易
Agent 全流程验证:
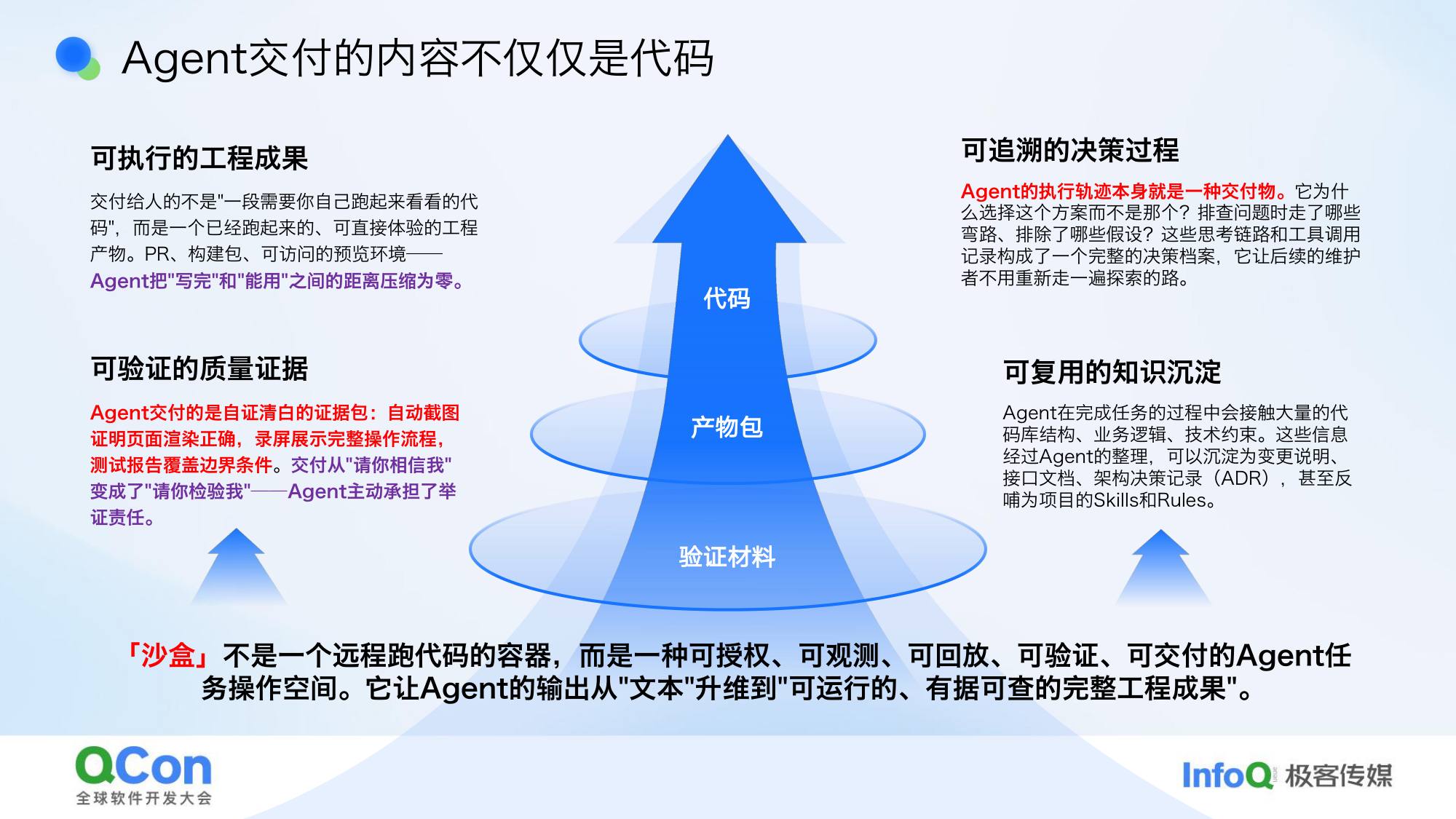
验证不是简单地跑一下就行,要验证整套逻辑。我们的做法:通过沙盒,把验证过程完全交给 AI——不是一个执行远程代码的服务器,而是一个可授权、可观测、可回放、可验证、可交付的 AI 专属环境,就像给 AI 一台专用电脑,搞坏了重新开一个就行。
交付物的变化:AI Agent 交付的内容不只是代码,还包括:验证截图、执行轨迹文档、质量证据。从”你相信我没问题”变成”请你检验我”——AI 写完代码后,给你看它的验证截图和全流程记录,你来判断结果准不准。
Harness 的两个层次
Harness 工程往前倒一步是”上下文工程”,本质是给模型看到的信息做精准控制。
Harness 应该分成两层:
- 给 Agent 构建者的 Harness:处理边界条件、工具设计、上下文工程
- 给开发者/用户的 Harness:每次 AI 写完代码后,如果某个地方写错了,记录下来,未来写代码时作为参考——这是一种技术约束,在教 AI 怎么做
六、总结
飞轮怎么转:
- Feedback Loop 提供信号(线上数据观测、异常发现)
- Benchmark 指导优化(场景化评测、四象限异常值分析)
- Agent Engineers 承接持续演进(全员转型、打破边界、人在回路)
核心建议:构建一个 Feedback Loop,让它能在本地跑 Benchmark,发现异常值,而不是盯着分数去强化训练。不要因为模型的每次发布,让整个 Agent 框架感冒。
Q&A
观众:什么样的公司适合做自己的 Coding Agent?
牛万鹏:凡是上规模的大企业,我都建议尝试自己做,但不是从零做——可以基于 Claude Code 等开源方案改,在里面加入自己的逻辑。原因:大企业有复杂的工作流,单纯靠原生工具很难把内部流程串起来。
小企业就很难回答了,最终哪些能活下来我也不知道。
大家想想 Cursor 是什么时候火的?2024 年 8 月,一个小女孩和她爸爸在推特上分享了用 Cursor 完成了一个项目。到现在 Cursor 仍然很强。这个领域的竞争格局很难判断。
观众:工具希望做成什么样?模型希望做成什么样?
牛万鹏:
工具:希望都能 CLI 化。百度现在所有的研发工具——需求管理、代码管理、邮件、平台——都已经 CLI 化,再把 CLI 命令包装成工具,AI Agent 就能轻松调用。无论是 MCP 还是其他方式接入,底层都应该 CLI 化。
模型:最基本的诉求是接口参数不要老变。比如 Claude 某版本加了新的思考参数,本来有产出的那些开发者,为了引入新参数要重新开发,其他开发者还要去适配——希望模型底层基础设施保持稳定,效果提升就好,别老改参数。
观众:多仓库场景下隐式依赖关系怎么处理?以及沙盒里测不了的深层业务流程怎么验证?
牛万鹏:
多仓库:用工作区(workspace)的概念,可以同时导入多个目录。但你说得对,企业级场景下微服务之间的隐式依赖,你不知道的仓库就不会放进来。这块目前还是需要人来告诉 AI”我在开发这个功能,相关的就这 10 个仓库”。
深层验证:沙盒里确实有些测试做不了,比如涉及 DTS 任务、下游数据计算的业务流程。我们在探索:当沙盒测不了时,让 AI Agent 感知到,自动推到流水线部署到测试环境或预生产环境,再去调那个环境的 API 做验证。这个方向还没有很好的解决方案。
观众:异常值覆盖充分性怎么保证?人在整个交互中应该关注什么?
牛万鹏:
充分性:测试工程师维护一份 Harness 文档,定义验证时应该测哪些功能、回归哪些部分。测试保障 AI 的底线,新需求时研发要写小的 PR 文档,先做计划,再让 AI 验证。
人应该关注什么:关注两头——开始时把问题和目标说清楚,结束时看结果准不准。中间 AI 怎么执行,完全黑盒就好,不用管。
具体做法:把验证流程写清楚成文档,让 AI 按照这个流程验证,并且告诉它哪些是关键检查点、要达标。当我们知道 AI 会走某个策略时,反过来看 AI 应该怎么做——如果 AI 像人一样去执行,那就对了。