QCon 2026·PayPal:Agent in Practice——从支付迁移落地到评测驱动进化
主讲:郁丁鑫(PayPal,Senior Manager - Software Engineering)
主讲:耿树朋(PayPal,Staff Machine Learning Engineer)
时长:约 54 分钟
把 1-1.5 个月的支付迁移工作缩短到 10 分钟——PayPal MAIA 项目的完整实践。核心是 EERO 循环(执行→评估→反思→优化),以及通过 Noise Injection 构建 150+ 种噪声类型的测试数据工厂,让 Agent 在对抗性测试中持续进化。
背景:为什么要做 MAIA
PayPal 的支付产品已经迭代了好几轮,提供了非常好的支付体验。但很多商户还在用 10 几 20 年前的老技术栈,用户的支付体验非常不友好。PayPal 花了很大精力帮商户做迁移,但摩擦很大:
- 代码改动大,客户很多不懂代码
- 哪怕懂技术,理解老 API(如 NVP——一个很老的协议)的业务语义也很费劲
- 找人来做,费用几千块,周期 1-1.5 个月
借助 AI 的热潮,我们创建了 MAIA(Multi-Agent API Integration Agent),帮助商户在升级过程中尽可能减少摩擦。
MAIA 的价值:
- 加速:把原本 1-1.5 个月的迁移工作缩短到 10 分钟
- 鲁棒性:把老 API 的业务知识蒸馏进 Agent,商户不用关心 API 的具体用法
- 简化:整个升级只需三行命令,token 消耗约 10 元人民币
- 不破坏原有代码风格

MAIA 的工作方式(Live Demo)
假设我是一个小型商户,网站用的是老版 PayPal API 技术栈。MAIA 提供了一个类似 Claude Code 的安装方式——通过命令行唤起 Agent,把安装包部署在商户自己的机器上,基于 Claude Code CLI,把相关 Skill 加载进去,逐步完成整个产品升级。
关键设计:Agent 托管在商户自己的环境里,在商户自己的网络环境中对自己的网站做升级——我们全程看不到商户的代码。
迁移只是第一步。迁完之后,商户还可以继续用 MAIA 做业务场景的集成和扩展——先扔掉历史包袱,再接入更多新产品。
郁丁鑫:MAIA 的架构与演进
开发心路历程
这个项目很早就有想法,随着 AI 能力增强逐步迭代。每个阶段不是推倒重来,而是留存前一阶段的东西,在下一阶段继续迭代。
阶段一:Prompt 工程(2025 年 Q2)
当时最大的概念是”后台编程”,选取合适的 Prompt。MAIA 要分析商户代码、找到集成位置、从老版本升级到新版本,单靠 Prompt 根本做不到。这个阶段学到最重要的东西是:如何保证 guardrail——不能让 Agent 过度发散,要把它限制在最小化改造的范围内。Vibe Coding 用户应该有感受,没有足够好的 guardrail,Agent 会做出让人无法理解的事情。
阶段二:Agent 框架
这时候 Agent 概念开始普及,我们用了 LangChain 等开源框架,加入 planning → 执行 → 自我修正的循环。但受限于上下文处理能力。
阶段三:One-shot + 上下文工程
把大量精力花在如何处理上下文——提前做总结,对上下文中不好的知识提前蒸馏,减少 Agent 运行时的”脑裂”。
阶段四:Harness + Feedback Loop
最近比较火的方向。这个阶段最大的体会是:AI 有一定的欺骗性——给它一个复杂场景,它会说”我做完了”或”这个太复杂我不做”,但其实只是在大模型外面套了一层壳,没有真正完成。
解决方案:把规划者(Planner)、验证者(Verifier)、修复者(Fixer)拆开。当验证者和修复者独立存在时,Agent 就很难自我满足——必须有测试用例告诉它”你要完成这个才算真正完成”。这是我们在 Harness 一年实践中得到的最重要的总结。
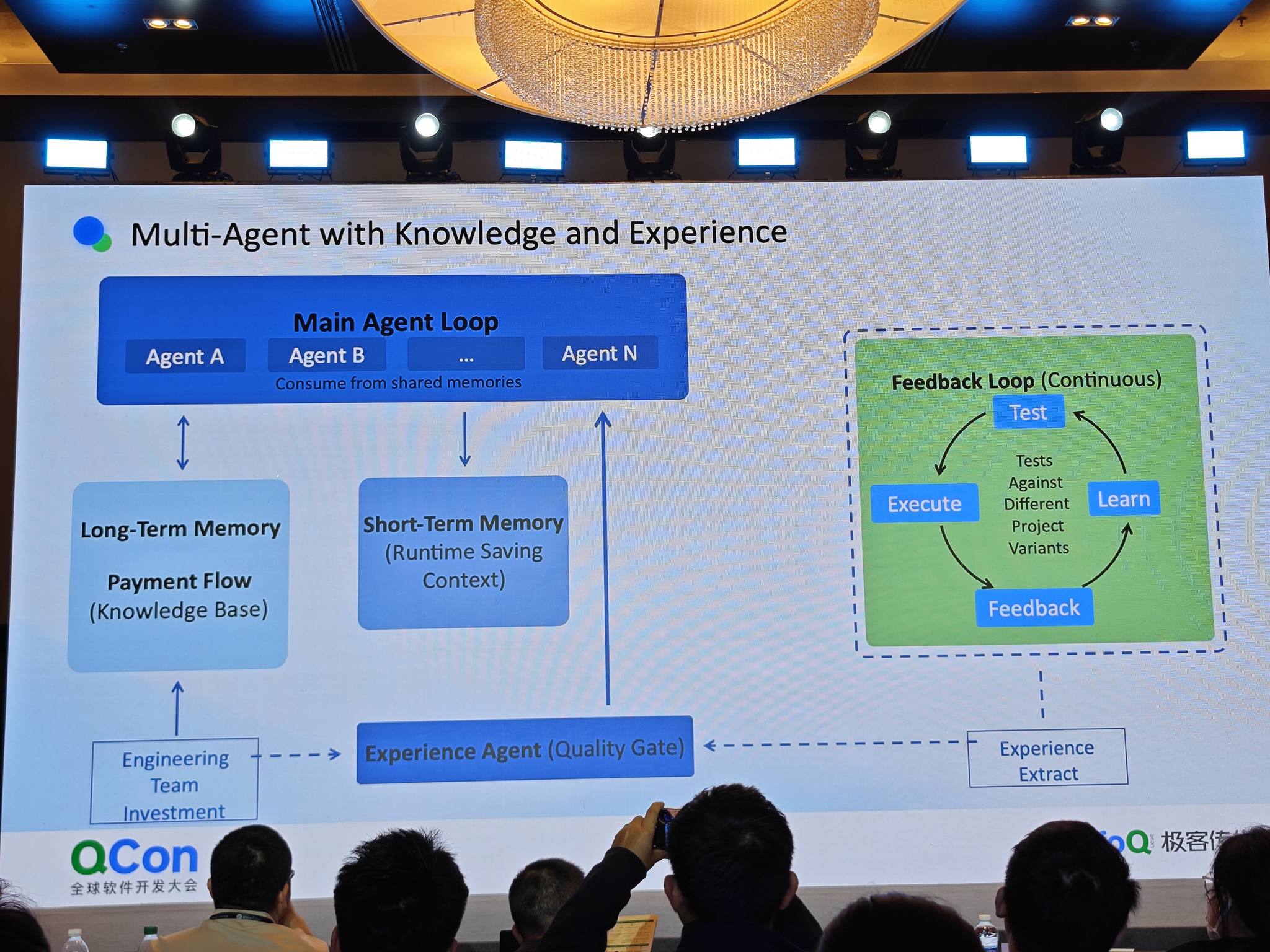
MAIA 架构
核心是长期记忆 + 短期记忆的结合:
- 长期记忆:把历史上老 API 的经验蒸馏成 Skill。这是工程师团队花精力最多的地方——很多内部文档已经丢失,需要大量时间重新蒸馏历史记忆
- 短期记忆:Agent 运行时分析商户代码的过程,把知识反馈给执行者、验证者、测试者
Skill 的核心价值:不只是把成功案例放进去,更重要的是把 corner case——Claude Code 等模型一直会犯错的地方——提取出来,变成 Skill 中的参考。同时,正确执行的状态也要指标化,确保模型按照框架走,而不是在”蒙对”。
Feedback Loop:通过一系列测试和指标,让 Agent 汲取足够多的经验,反馈给长期记忆,形成闭环。
耿树朋:评测体系的设计
接下来我介绍 MAIA 的评估是怎么开展的。
MAIA 有一个特殊的挑战:Agent 托管在商户自己的环境,我们看不到商户的代码,但要做一个能准确完成 legacy 代码迁移的 Agent,还要保证执行过程稳定可复现。
这里用到了 EERO 循环:Execute(执行)→ Evaluate(评估)→ Reflect(反思)→ Optimize(优化)。
执行环节:如何摸清商户代码情况
我们对 PayPal 几百万商户的 API 调用数据做了排查,看到了清晰的长尾分布。头部是一些开源电商平台(Magento、ZenCart、Medusa 等),占了相当大比例。
基于此,我们筛选了 6-7 种开源电商平台,覆盖 Java/PHP/JavaScript/C# 四种语言和多个版本,作为 MAIA 初步开发和评估的基础。
评估环节:三个核心问题
问题一:如何提供确定性的测试?
综合了传统测试范式和新的 AI 方法:
- Function test、Unit test
- 基于 Playwright 的端到端测试:覆盖完整的买家→卖家链路(landing 页面→选商品→加购物车→结账→退款),完整覆盖 PayPal SDK 的调用过程
问题二:6-7 个网站够吗?
不够。我们需要覆盖更宽广的卖家可能性,确保测试空间有足够稠密度。解决方案:数据合成——通过 Noise Injection 自动生成大量测试变体。
问题三:可复现性
一次成功和多次成功的概率要保持一致。基于测试方案 + 数据合成,搭建了自己的回归测试 pipeline。

Noise Injection:Multi-Agent 驱动的测试数据工厂
这是一个类似 GAN(对抗生成网络)的设计:生成器(MAIA)负责做代码升级,判别器负责评判升级是否成功。
Noise Catalog:4 个层级,150+ 种噪声类型:
- 语法层噪声:把变量名换成拼音或随机字母,添加与代码逻辑不符的注释,干扰代码理解
- 结构层噪声:把多个类合并成一个文件,甚至合并进一个 main 函数
- 业务逻辑层噪声:加入红包、折扣等活动逻辑,影响支付调度链路
- 架构层噪声:替换支付路由和设计模式,把 PHP 代码换成 JS 写,引入新依赖
逐级增加难度,不断挑战 Agent 的代码理解能力边界。
循环流程:
- MAIA 拿到带噪声的 legacy 代码 → 尝试升级
- 升级成功 → 加入成功 case 仓库(用于回归测试)
- 升级失败 → 加入失败 case 仓库(用于定点 review)
为了引入更多随机性,我们还加了一个”降级”设计:让模型扮演不同风格的工程师画像(20 年经验只写 PHP 的资深工程师 vs 1 年经验只写 React 的初级工程师),从新版本再降级回旧版本,生成更多样的测试变体。

可观测性工具
一个 MAIA 升级过程可能有几百轮大模型交互,原始 trace 数据动辄几十 MB,人根本看不完,AI 来 review 也会撑爆上下文。
我们自己做了可观测性工具:以图识图的方式,把所有 Agent/Skill 交互以可视化视图从上往下展示,附带时间消耗、token 消耗、工具调用信息。这相当于给整个数据建索引,后续 AI 访问这些数据时效率也高很多——符合渐进式披露原则。
Evolution Engine:EERO 循环的反思与优化环节
数据收集:来源包括 Comate 执行体系、测试报告(Playwright 产生的截图/HTML)、sandbox 环境日志。用 ETL 脚本编排成预定义模板(索引文件),让后续 AI 访问时不会撑爆上下文。
多维审查:用专门的 AI Agent 对运行轨迹做多维度 review,大量使用”模型作为裁判”技术。
交叉验证:
- Confidence level 要达到阈值(如 0.75)
- 多个 AI Agent 参与,必须全部同意才能输出(投票机制)
- 扔掉互斥信息,聚合成有价值的通用知识
关键学到的东西:RCA 追求准确率,不追求全面。一次 RCA 只输出一个,但要它是准确的。如果这一个准确,人看了认可,下一轮迭代再补第二个。不要试图一次把毛巾里的水全拧干——每次只挤一滴水,通过迭代让这件事变轻松。
成功 case 和失败 case 同样重要:只关注失败容易过拟合。用向量空间距离筛选与当前 case 相似的历史成功 case,和失败 case 一起 review——成功的经验帮助过滤掉那些”两边都有”的噪声错误,降低幻觉率。

技术架构演进
Claude Sonnet 4 时代:模型的指令跟随能力比较差,需要很多手动操作。执行引擎:Claude Code;长时运行 Harness:Claude Agent SDK;上层控制图:LangGraph。
Claude 4.5/4.6 时代:迁移到纯 Skill 方案,去掉 LangGraph 依赖。好处:
- 依赖变少
- Skill 里可以嵌入大量 reference 文档和确定性脚本,提供确定性信号
- 新业务来了,一两天就能校验原有 Skill 重新组合后能否满足要求(原来要一两周)
Multi-Agent 协作的关键工程经验
经验一:Agent 间接口必须强约束
多个 Skill 协作时,必须写清楚交接接口——输出文件叫什么名字、放在什么位置、开头有哪些字段。
不这么做的后果:Agent A 输出时没按预定格式写某个字段,Agent B 来读时,Claude 会”脑补”——“虽然他没写,但我觉得应该是这样”——然后基于 A 的局部信息 + 脑补内容继续运行,非常不稳定。
通过 hook 和外部 shell 脚本在特定阶段做确定性校验,才能保证信号可靠。
经验二:每个阶段结束后主动压缩上下文
MAIA 这种长时运行、多轮交互的任务很容易触发上下文压缩。每个 Agent/Skill 执行结束后,主动做一次清晰的阶段性压缩,是非常有效的方式。
经验三:多模型辩论优于单模型
实验结论:同时用 Claude Opus 4.6 + GPT-5.2 Codex + Gemini 3 Pro 扮演相同角色进行辩论,效果优于同一家模型的多个实例辩论。不同家的模型在各自擅长的领域不同,综合多个模型的输出,能得到更全面、更有深度的报告。
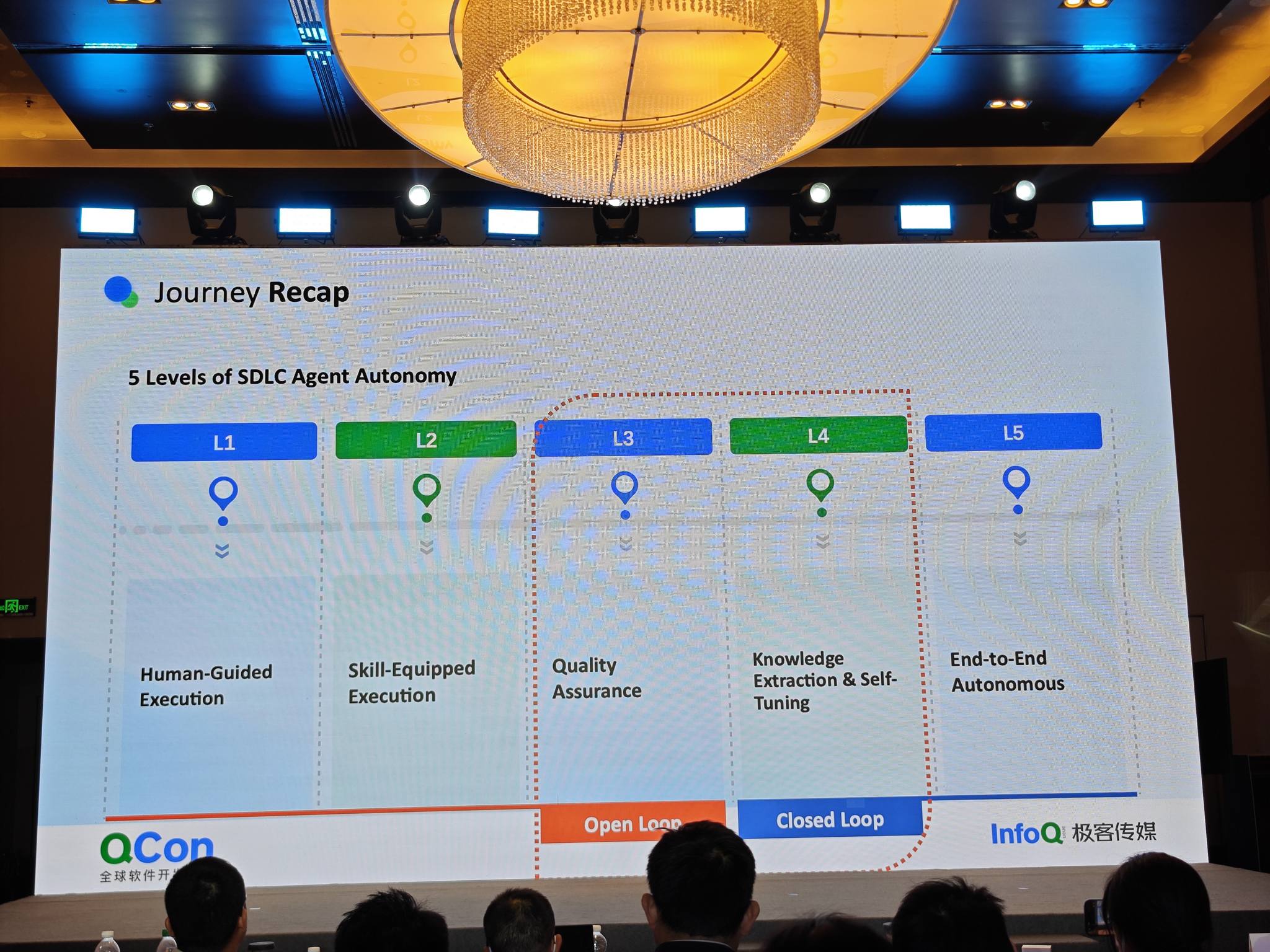
SDLC 自动化的五个层级
这个框架可以推广到 SDLC 的任何子模块:
| 层级 | 描述 |
|---|---|
| L1 | 工程师手动与 AI 对话,指导完成任务 |
| L2 | 把经验固化成 Skill,执行自动化 |
| L3 | 有了自动化执行,就要有自动化测试 |
| L4 | 验证自动化,AI 能自己判断 Skill 是否成功,开始自我修复 |
| L5 | AI 自己提取变更内容,推新一轮测试,验证是否比过去更好——落入 RLRO 范式 |
L5 就是 RLRO 范式:Setup(L2)= RL 的数据准备;Rollout(L3/L4)= 执行与评估;Rollback = 失败时回退;Optimize = 基于奖励触发下一轮实验。
核心原则:永远面向未来做 Skill。做一个 Skill 时,不要太关注这次执行成功还是失败,而是想:如果未来要做同样的事,我从这个 case 里应该学到什么?
Q&A
观众:交付给 Agent 的业务知识具体是什么形式?
郁丁鑫:主要是 workshop(工作流文档)+ reference(参考文档)+ 解决方案。
以 NVP 为例,我们写了大量 reference,让 AI 读懂 NVP 里各个字段的含义。针对 PHP、Java 等不同语言,我们会用伪代码把 API 的语义描述清楚,作为参考。当 Agent 识别到用户在某个特定业务领域时,通过伪代码生成对应语言的实现。
本质上有两个概念:老代码 + 伪代码(业务语义),加上转换后的新代码。Agent 在运行中同时参考这两个,根据我们的要求完成转化。
观众:动态构建的参数怎么处理?迁移后的线上验证怎么做?
郁丁鑫:
动态参数:第一次让 Agent 先走完整个流程,定义好所有测试标准和期望值。如果没达到期望,结合历史迭代循环告诉它要往哪个方向走,最终把动态参数塞进去。这个过程需要打补丁,不是一次就能成功的——目前 MAIA 大约 90% 的情况能一次成功,5-10% 需要自己迭代 2-3 轮。
线上验证:测试包和整个 conversion 过程是独立的,商户可以在自己的机器上保留测试包,把结果反馈回来。实际上,迁移和升级过程中我们都会让用户先走沙盒环境,走完整路径后再复制到线上。
观众:未来的软件交付方式会变成什么样?
郁丁鑫:
我们现在的交付不只是一个产品,而是 Skills 集合 + 测试集。
未来的设想:针对某个支付场景(比如 PayPal),我们给一套标准的商户集成方案,定义完整的测试策略。只要这套完整测试都能达标,集成就是完美的。
未来交付给用户的不只是支付产品,而是一个完整的验证生态——这才是新的软件包交互方式。测试集是核心,比 Skill 本身更关键。
这个平台本身是一个 CLI 工具,通过 CLI 才能把完整的端到端流程走通。