QCon 2026·网易:从 Vibe Coding 到 Spec Driven 的智能化软件工厂实践
主讲:姜天意(网易智企,CodeWave & CoreAgent 技术负责人)
时长:约 50 分钟
Vibe Coding 解决了速度问题,但带来了质量和可控性问题。网易 CodeWave 通过 Spec Driven Development + Harness Engineering 的组合,把需求标准化(EARS 语法)、技术设计约束、沙箱验证串成完整流程,并用自研 NASL DSL 和代码大模型训练形成闭环。
开场
大家好,非常荣幸第三次来到 QCon。CodeWave 大家可能有所了解,是一个 to B 的 AI 软件研发平台,以低代码和 AI Coding 为主。
今天我要回答一个问题:现在 AI Coding 发展这么好,可视化低代码还有没有存在的必要?Spec Driven 又是什么,它怎么解决 Vibe Coding 的问题?
我来自网易智企 CodeWave 业务中心,负责 CodeWave 和 CoreAgent 的智能体与知识库平台。今天分四个部分:
- 为什么要把 Spec Driven 和低代码、AI Coding 结合
- 怎么做需求标准化驱动的 SDD
- 几百页大 PRD 下如何做复杂任务的 Harness Engineering
- 怎么训练自己的代码大模型,以及用 Benchmark 度量产品效果
一、Vibe Coding 的问题与 Spec Driven 的提出
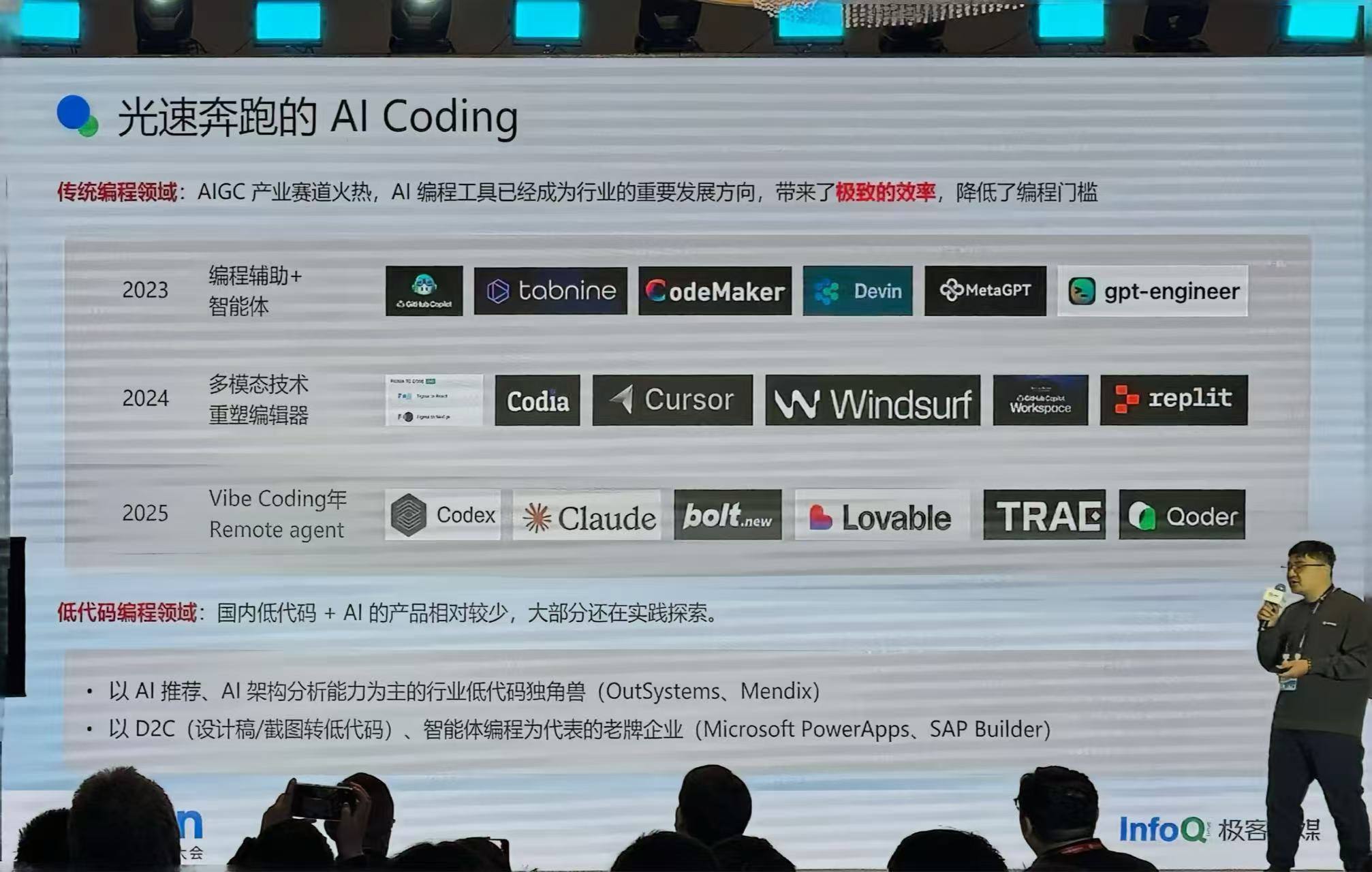
AI Coding 的发展脉络
过去三年发展极快。2023 年还是 Copilot 时代;2024 年出现了大量编辑器重塑,Cursor、Windsurf 是其中的佼佼者;2025 年我们称之为 Vibe Coding 元年——大部分编辑器推出了自主编程能力,代表就是 Claude Code 和 Cursor。这些工具很大程度上改变了传统软件研发的格局。
反观低代码,感觉是很”low”的技术,这几年 AI + 低代码的产品比较少,大部分还在探索。
Vibe Coding 的真实问题
2025 年开发者调查报告显示:60% 以上的人认为 AI Coding 显著提升了生产力,但真正能信任 AI 生成代码的只有 3%。

AI 生成代码有几个核心问题:
技术栈不受控:AI 生成的代码风格迥异,倾向于用国外流行的 Next.js、Tailwind 等技术栈,和国内企业现有代码仓库兼容性低。
代码可维护性差:很多人用 AI 写代码,只能用 AI 来 debug,没有好的维护方式,只能不断地”兑换”(重新生成)。
缺少业务理解:在复杂系统里,业务知识的微小变化可能造成生成结果的巨大偏移。
问题的本质:自然语言的模糊性
48 年前,算法大师 Dijkstra 就讲过:自然语言编程是非常愚蠢的事情。

为什么?数学的约束是形式化的符号,你在写形式化符号或编程代码时,同时在做思考和抽象。但用自然语言编程,你想到什么就写什么,AI 写得很快,但缺少了思考。
另外 AI 总是漏需求——你以为说清楚了,AI 表现得像是理解了,但实际上存在巨大歧义。GPT-4、早期 DeepSeek 特别喜欢”奉承”开发者,看起来理解了,其实没有。
还有一点:上下文越长,整个开发质量越来越降级。大模型的服从性反而会变成很大的问题。
核心问题是:无法指望用户写出高质量的提示词,而且自然语言编程缺乏文档、单元测试和架构约束。
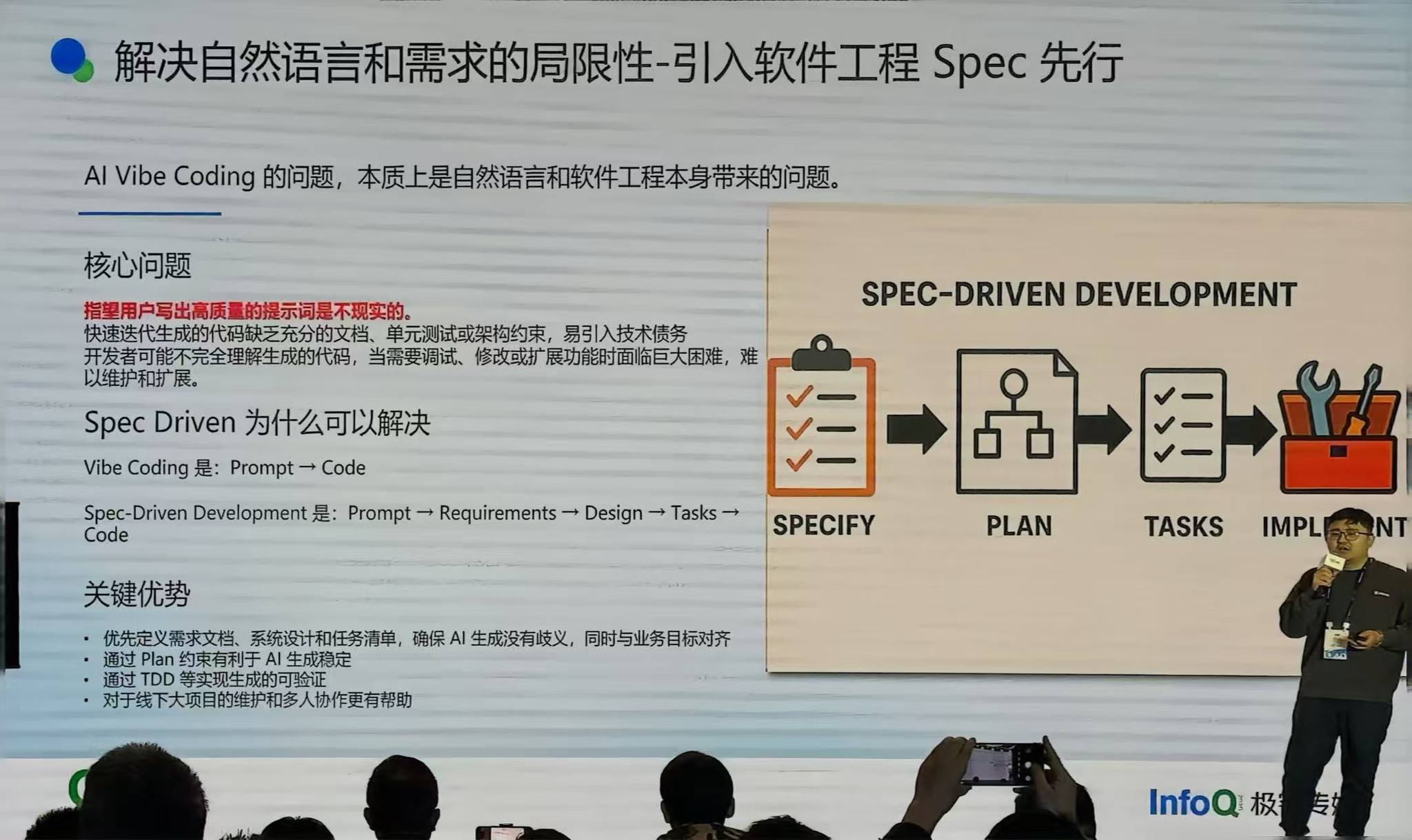
Spec Driven 的理念
去年,亚马逊发布了 Kiro,在 AI Coding 工具中引入了 Spec Driven Development(SDD)的工作流,推动 SDD 进入主流视野。
Vibe Coding 的过程是 Prompt 驱动的;SDD 是:先 Requirements(需求标准化)→ Design(技术设计)→ 任务拆解 → Code。
几个关键点:
- 先把需求澄清清楚,确保 AI 在理解需求上没有歧义
- 通过 Spec Design 把技术设计和架构约束澄清清楚,用公司的技术栈和目录结构约束 AI 生成
- 通过 Plan 约束,有利于 AI 生成的稳定性(去年下半年几乎所有 AI 工具都上了 Plan Mode,这是 2023 年就有的智能体模式,Manus 是其集大成者)
- 通过 TDD 实现可验证性
SDD 能解决什么:
- 代码质量不可控 → 通过技术架构约束保证代码质量在可控范围内
- 可维护性差 → Result Driven Development(RDD):通过写各种测试用例保证结果对了就好了,不再纠结维护
- 业务理解不足 → 不断澄清产品需求,加入业务理解
但 SDD 不能解决所有问题。很多人会以为 SDD 就是一个大型提示词工程,把输入写得足够详细就行——事实并非如此。
Spec 的问题:
- 大模型要读得懂你的 Spec,很多模型读不懂复杂的 Spec,做不了好的上下文管理和指令遵循
- Spec 的编写成本非常高,生成出来的 Spec 人和模型都未必能看懂
- 复杂应用给到模型后,模型会把编码任务变成复杂的 Code Agent 长程任务,某个节点出现问题就会导致后面全部出问题,甚至无从排查
SDD 只能解决一部分约束问题。 这就引出了第二个概念:Harness Engineering。
二、Harness Engineering:驾驭大模型这匹快马
什么是 Harness Engineering
从 2023 年的 Prompt Engineering,到 2025 年的 Context Engineering,到 2026 年被广泛讨论的 Harness Engineering——本质是:构建一个舒适的环境让大模型去跑。

大模型是一匹快马,没有好的驾驭方案很容易跑偏,在复杂任务上可能失控。
Harness Engineering 包含两个核心要素:
规范:通过 Spec、CLAUDE.md、AGENT.md 等方式约束大模型的行为,这是形式化的规范。
流程控制:在大模型执行过程中,用类似 TDD、CI/CD 这样的流程性东西管控整个执行过程,用控制论的方法管理任务执行的稳定性。
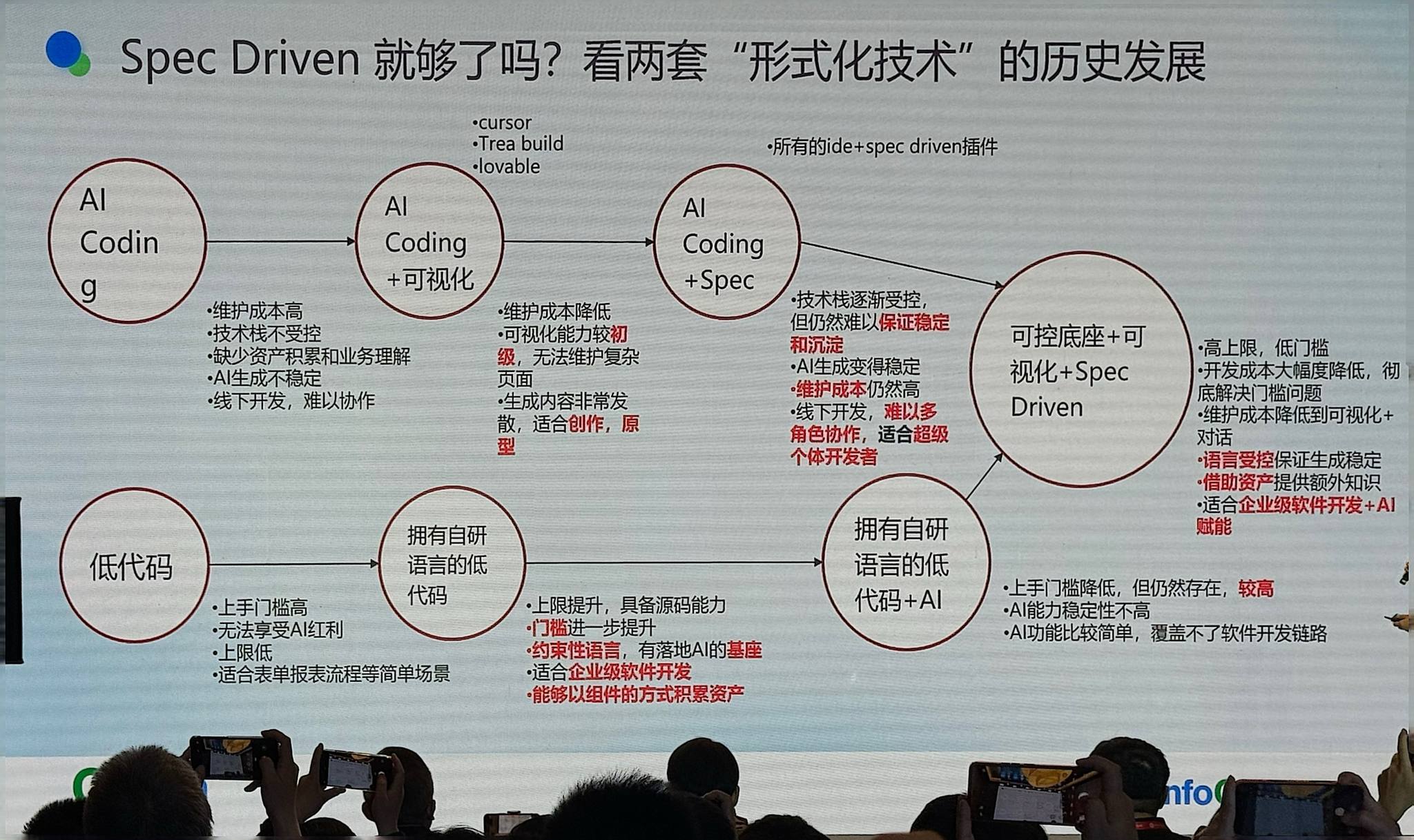
低代码 + AI Coding 的演进
早期:AI Coding 最早的问题是技术栈不受控、维护成本高。很多公司引入低代码技术——Cursor 早期也做过可视化能力,认为通过可视化界面可以看到 AI 生成的界面效果并直接修改。但这个方案开放性太强,没有足够的收敛能力,难以和代码做二次关联,只适合原型创作。
中期:AI Coding 引入 SDD,保证了技术栈受控,但大规模任务的稳定性仍然难以保证,维护成本高,而且只能给程序员提效,产品经理、设计师等角色无法参与。
现在:我们探索一条新路线——可控的语言底座 + 可视化开发 + Spec Driven,彻底解决低代码产品的上手门槛问题,同时通过专用的方式约束 AI 生成代码,借助低代码的资产沉淀、企业级全流程控制和多人协作能力。
三、产品介绍:需求标准化驱动的开发平台
平台核心流程(视频演示)
第一步(产品经理):导入需求文档,通过 7 个阶段智能分析,转换成标准需求文档,产品经理确认。
第二步(架构师):启动技术设计,智能体将标准需求拆解为架构设计(应用架构、数据建模、UI/UE 规范、领域服务设计等)和业务设计,架构师 review 并提出修改。
第三步:架构师将确认好的技术设计生成研发任务,执行架构相关任务(实体生成等),逐条或批量执行,智能体自动检测依赖任务。
第四步(开发组):按项目大小和工期分工协作,执行业务模块研发任务,可继续补充需求和设计细节,贴近真实开发场景。
任务阶段性完成后检查生成内容,修改调整后发布预览,所有模块完成后应用搭建完成。
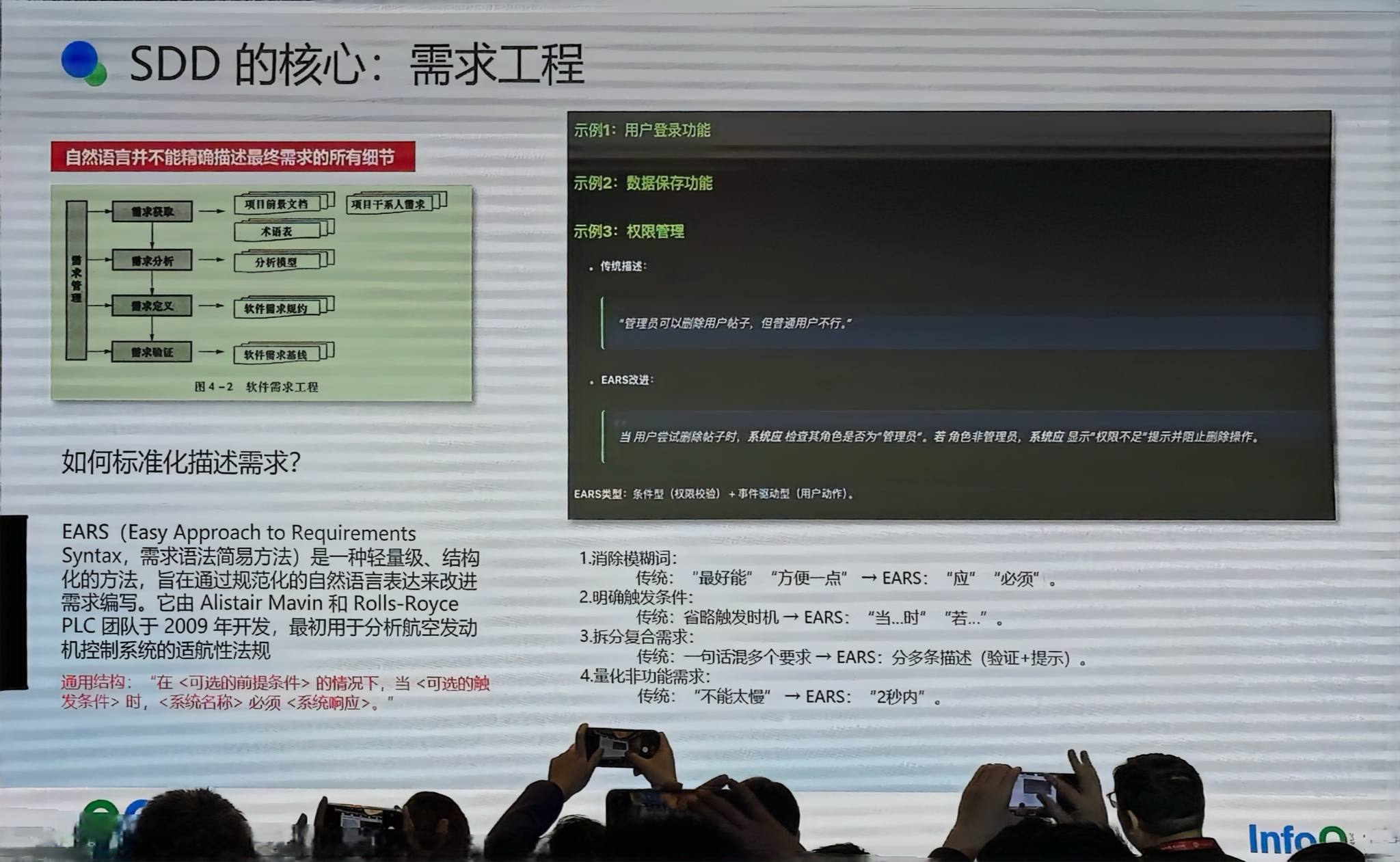
需求工程:EARS 标准
Spec Driven 的关键在于 Spec 怎么写——什么样的 Spec 人能看懂、AI 也能看懂。
我们选择了 EARS(Easy Approach to Requirements Syntax),一个非常轻量级的结构化需求描述方法,原本用于航天发动机控制系统。Kiro 也使用了这个语法。
EARS 的结构:在什么条件下,当(可选的)什么触发时,系统必须怎样。
举例:
原始需求:「系统应该让用户登录方便一点,出错时没有提示」
EARS 标准化:「当用户输入用户名密码并点击登录时,系统应验证凭据是否匹配,若验证失败,应显示’用户名和密码错误’」
原始需求:「用户编辑内容时最好能自动保存」
EARS 标准化:「编辑框停止输入超过 5 秒时,系统应自动保存」
需求标准化的核心:消除模糊词(”最好”→”必须”),明确触发条件,拆分复合需求,量化非功能需求(”不能太慢”→”2 秒内”)。
我们也调研了 User Story、Gherkin、需求模式等方案,最终选择 EARS,因为它语法简单、可测试性强,非常适合需求工程。
老系统改造:Code to Spec 逆向工程
to B 客户一个很大的痛点是老代码改不动。我们提供了仓库治理插件,可以直接在老代码里对话生成对应的 Spec,再把 Spec 导入到 CodeWave 平台,做源码解读 → 生成 Spec → 开发新系统。
重要的是,在重构过程中还要保持 API 一致性(避免下游依赖崩溃),所以不仅把需求放到 Spec 里,还把技术设计(API 接口)也放进去。

四、大规模 SDD 任务的 Harness Engineering 实践
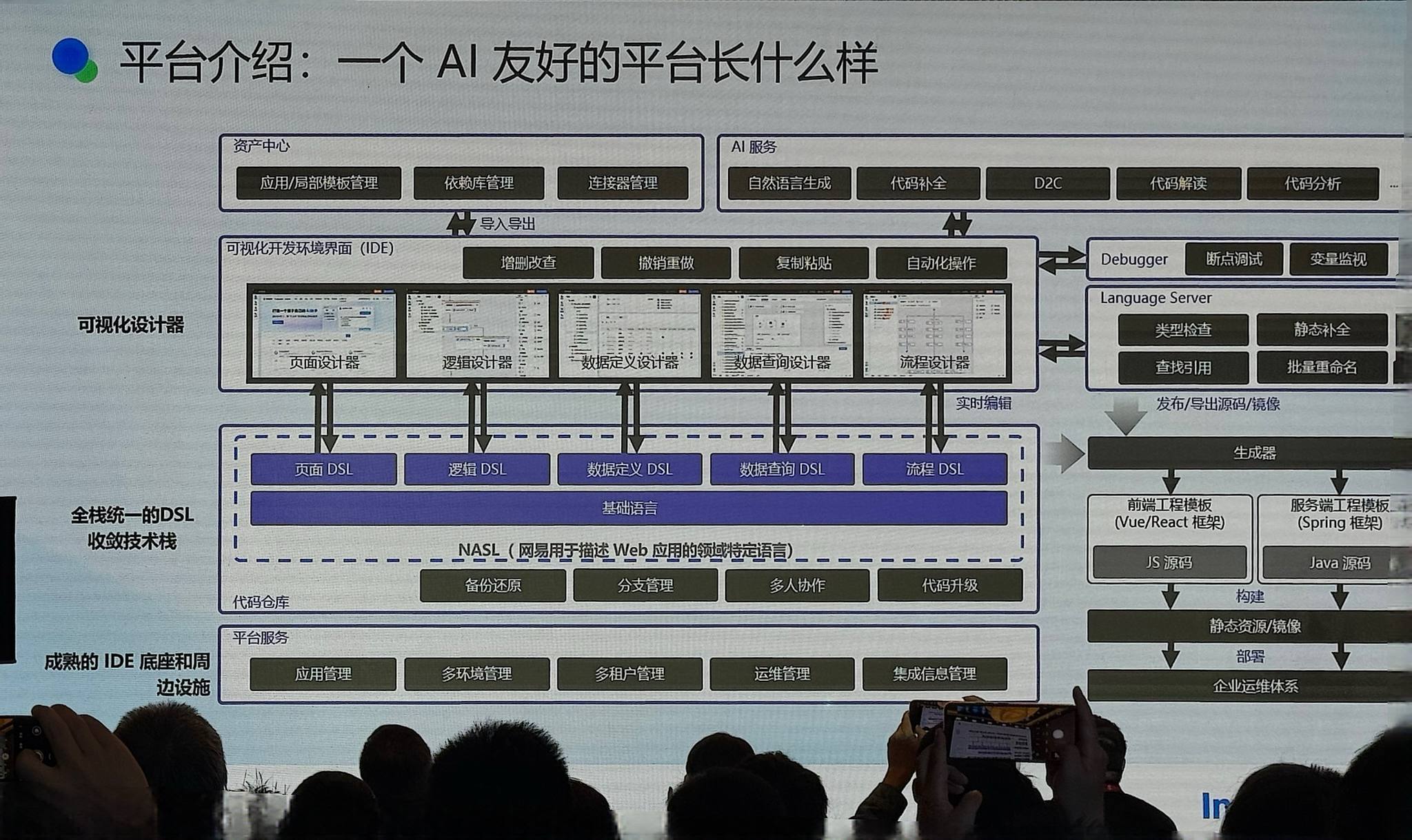
CodeWave 的平台底座
CodeWave 平台所有内容(页面逻辑、数据定义、数据查询)本质上都是自研 DSL NASL 的一部分,天然是一个约束性非常强的开发平台。AI 化改造相对简单,把可视化方式改造成 AI 交互输入就好了。
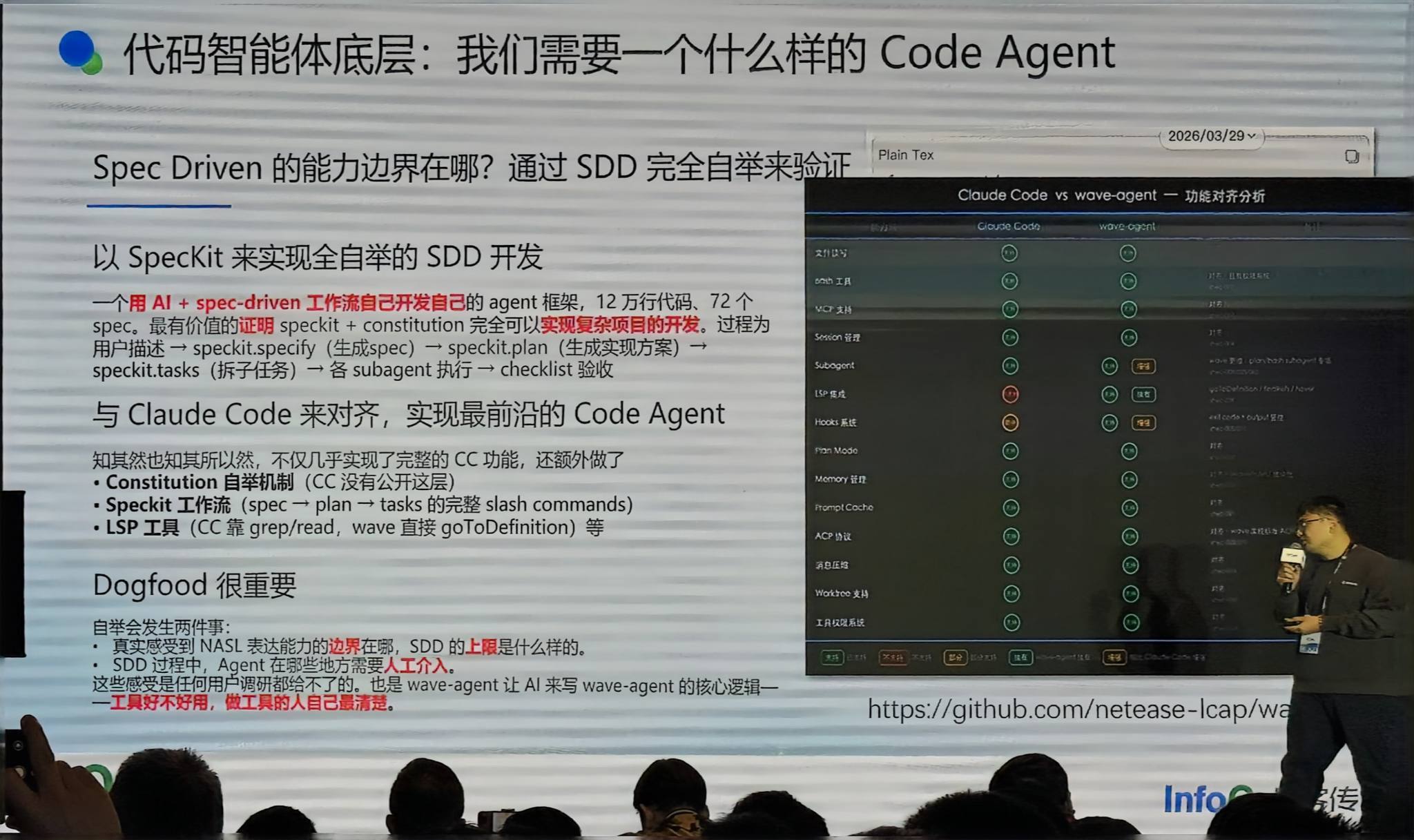
自研 Code Agent:Wave-Agent(开源)
我们做了一个自研的 AI Coding 工具 Wave-Agent,完全开源。为什么做这个?不是为了造轮子,而是为了”吃自己的狗粮”——这个项目完全由 Spec Driven 方式开发,12 万行代码,72 个 Spec,整个过程都用 SDD 开发,以此验证 SDD + NASL 能完成复杂项目开发。
相比 Claude Code,我们还增强了一些功能,比如 Language Server 工具支持(对 Java 应用尤其重要)、Spec 工作流和 CLAUDE.md 等。
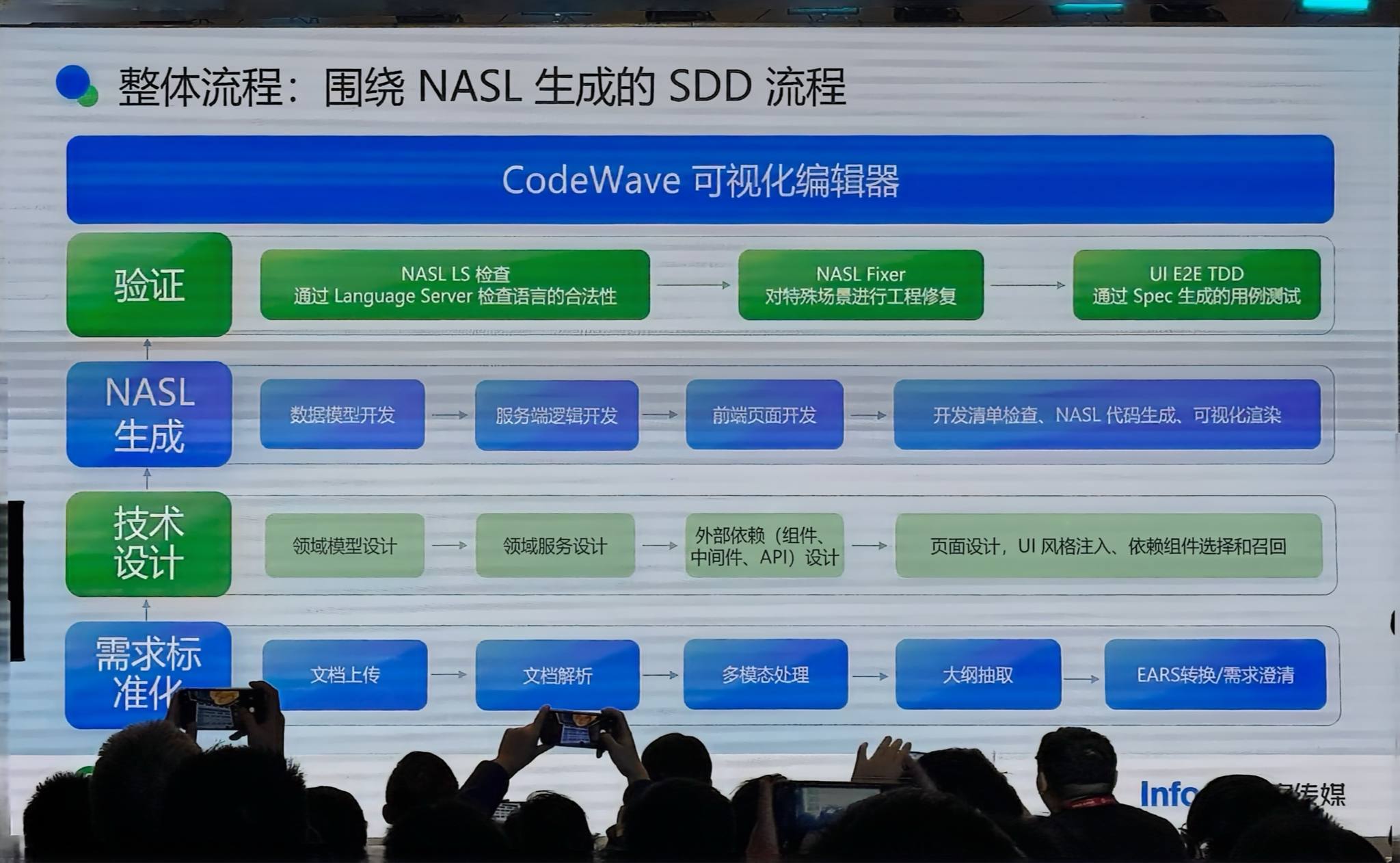
整体流程
- 需求标准化:文档上传解析 → 多模态处理(图片)+ 大纲抽取 → 生成 EARS 标准需求
- 技术设计:领域模型、领域服务、外部依赖,以及关键的 API Contract 层(前后端共同遵守的接口契约,避免前端猜接口)
- 代码生成:生成 NASL(数据模型、服务端逻辑、前端页面)
- 验证:沙箱环境运行,Language Server 校验,生成一对一测试用例
技术设计
技术设计生成给架构师审阅的完整文档:领域模型、后端逻辑、前端页面基本目录,再通过子 Agent 并发生成详细设计。依赖关系自动处理(Frontend 强依赖 Backend 接口结构)。

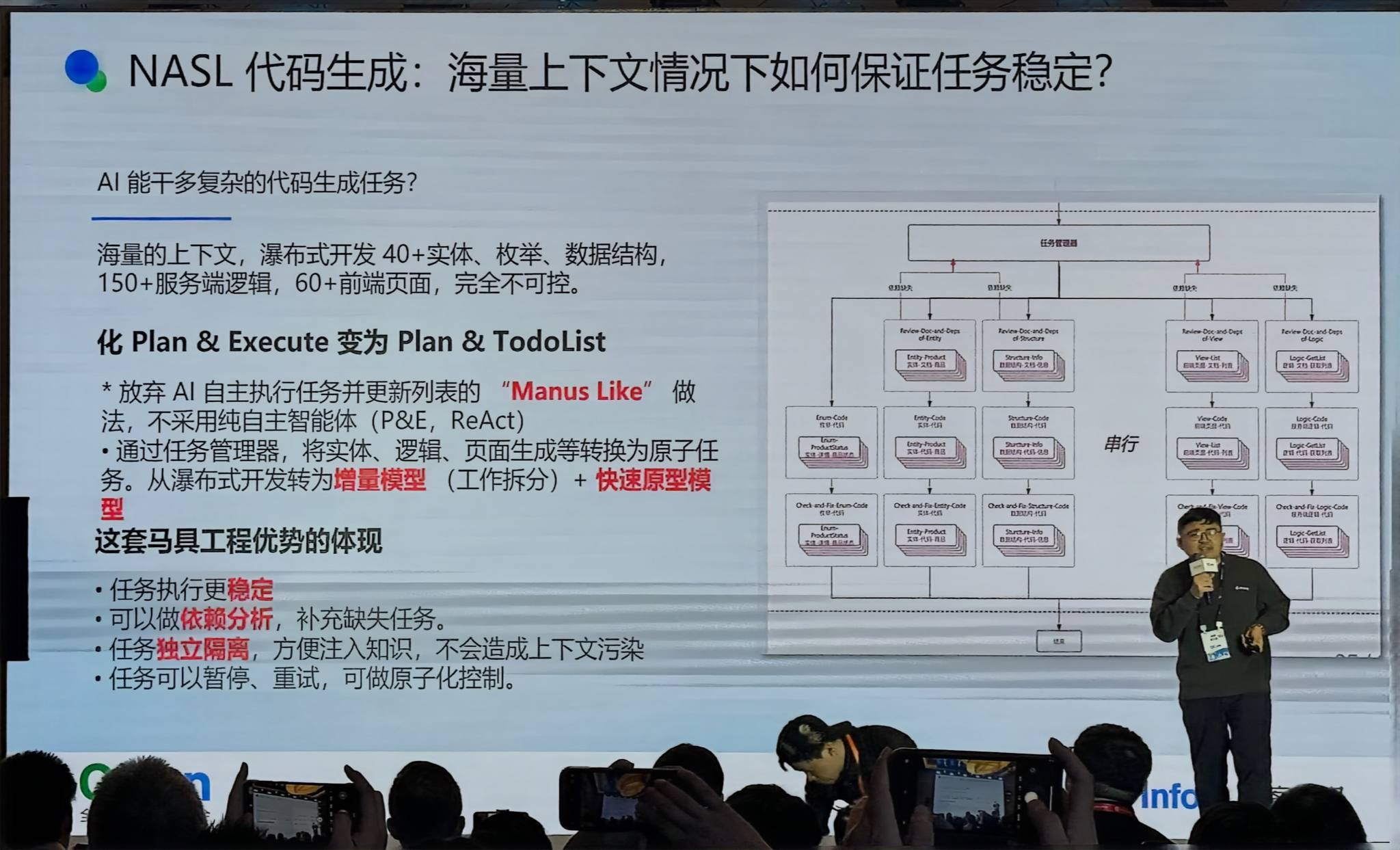
NASL 代码生成
海量上下文下如何保证任务稳定?放弃 Manus Like 的 AI 自主执行,改用 Plan & TodoList 模式——把 40+ 实体、150+ 服务端逻辑、60+ 前端页面拆成有序任务列表,逐步执行,防止上下文爆炸。
智能体架构选型
市面上三类智能体架构:
ReAct 模式(高开放性):Plan and Execute,最大限度借助大模型的任务规划能力。优点是开放性强;缺点是出了问题无法 debug,Manus 早期就有这个问题(任务跑一天断掉了也不知道发生了什么)。
Skill 驱动(中等灵活性):把下游实现转成 Skill 驱动,Skill 天然是渐进式披露的方案——把场景的实现固化下来,由 Sub-agent 上下文隔离驱动每个 Skill 执行。在特定 Skill 场景下表现非常好,上下文隔离,Skill 打磨好后任务稳定性很强。
Workflow(低开放性):固定流程引擎,不相信 AI 自己的编排能力。Token 消耗少,固定流程执行准确,但开放性差。代表产品:Dify、Flowise。
我们的选择:根据场景混用。确定性强的流程用 Workflow,不确定的交给 Agent 自主决策。
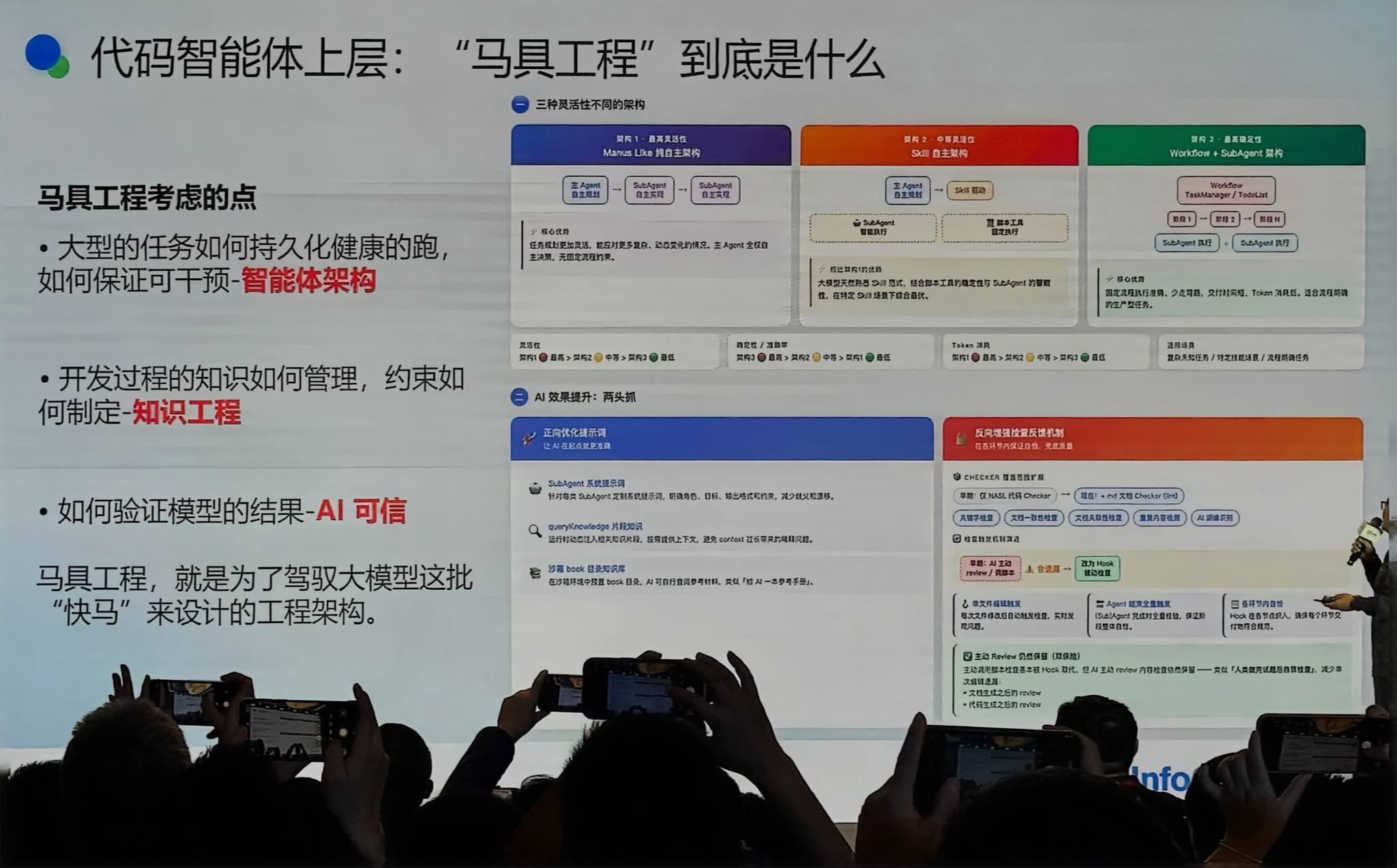
知识工程:渐进式披露
不能把所有知识全塞进上下文(大部分模型上下文超过 80K 会出现大规模幻觉)。参考 Skill 的渐进式披露原则:
- 摘要层:先告诉模型有哪些资源,每个资源负责什么领域
- 按需召回:提供 MCP 工具,模型自己决定需要什么就召回什么
- 文档化知识块:每个知识块不超过 1500 token,避免上下文爆炸
- Few-shot 补充:在文档里加上示例

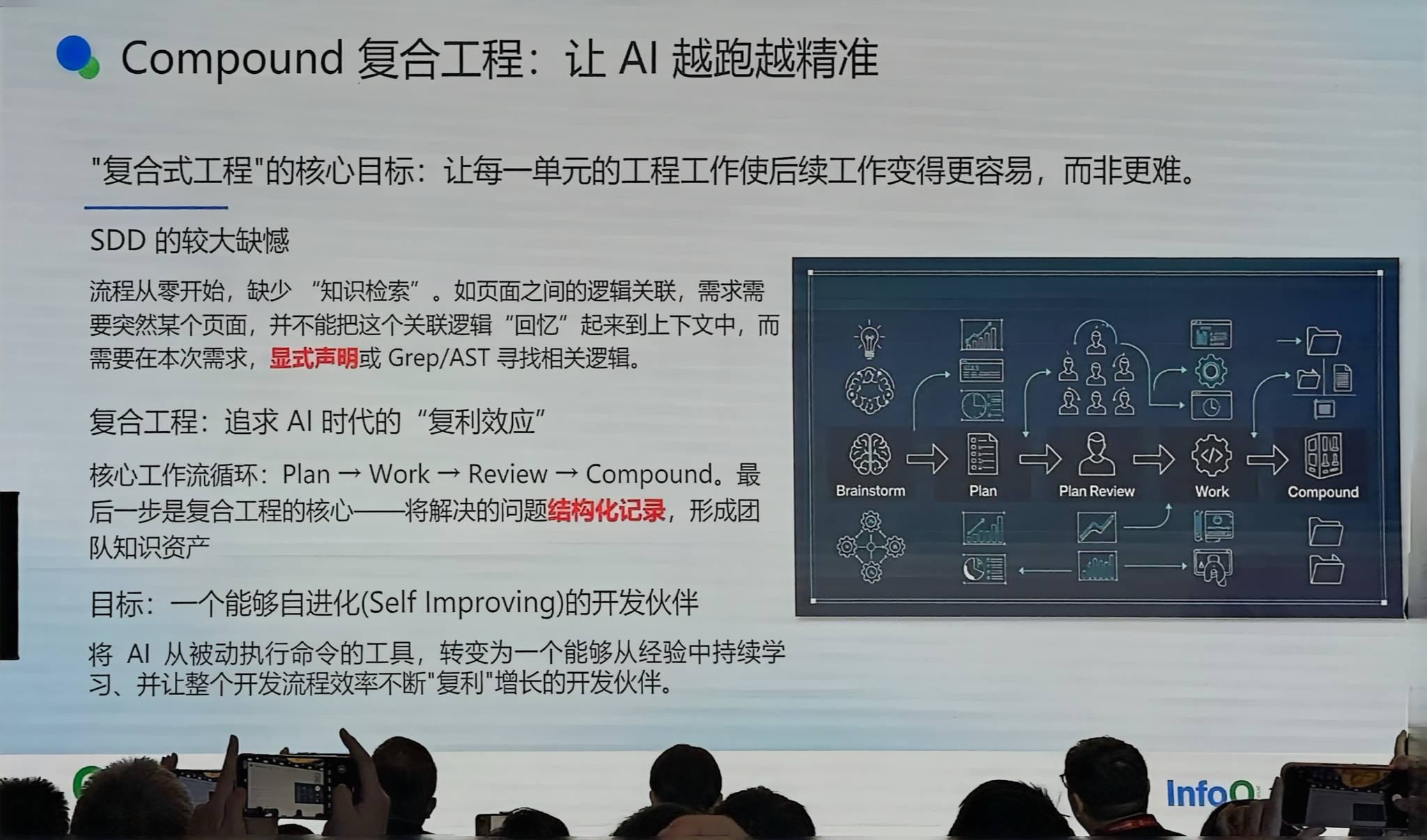
Compound 复合工程
在跑 SDD 的过程中,模型不知道之前做过的知识是什么样子——比如页面里有些关联是需求层面的,代码层面找不到。
我们引入了 Compound 复合工程:每次跑完后,总结经验,把解决的问题记录形成图,让智能体成为自净化的开发伙伴。Manus 最近也实现了类似功能(自己总结自己的计划)。
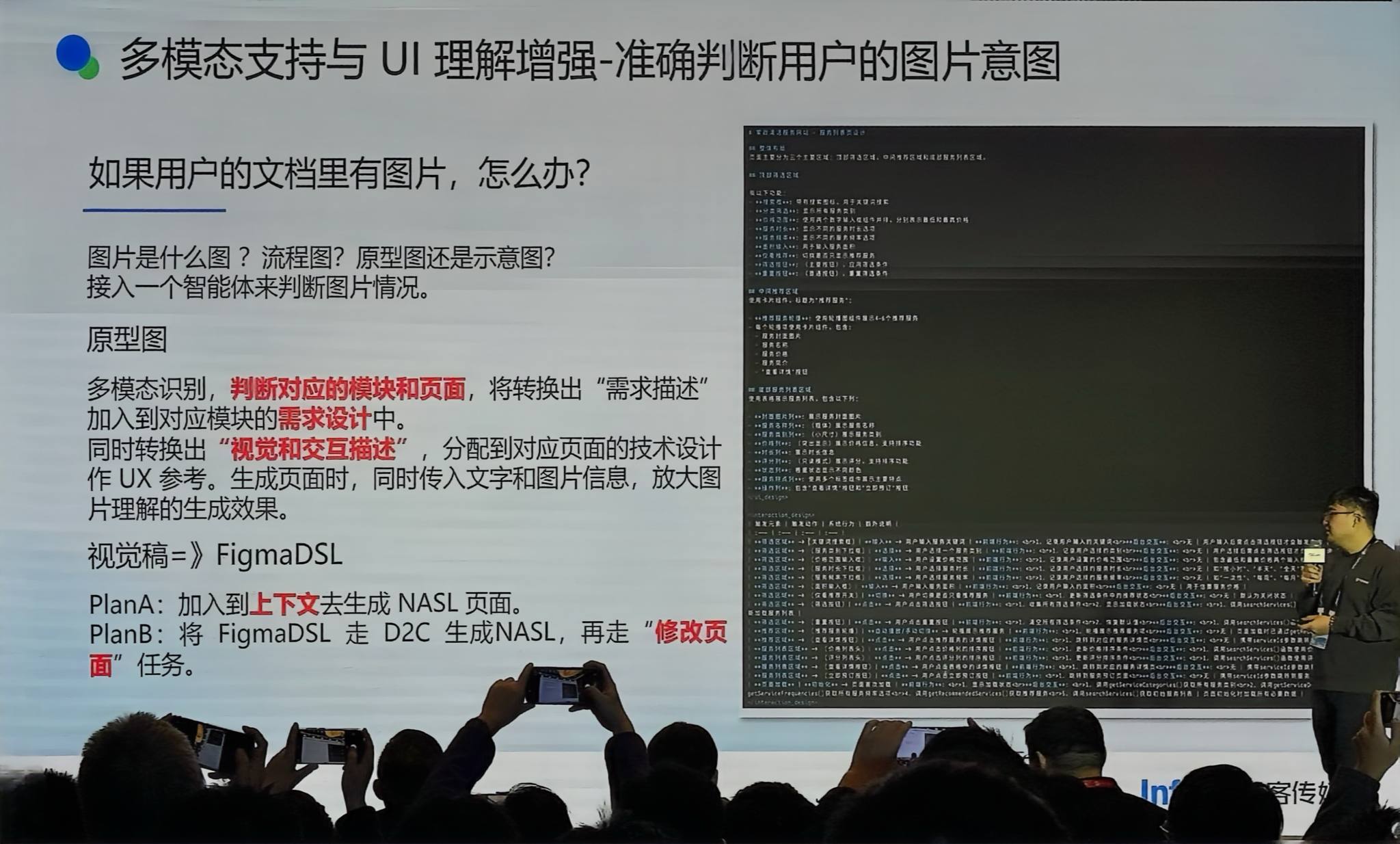
多模态支持
需求里有图片怎么办?先判断是原型图(需求描述)还是视觉参考:
- 原型图 → 转成需求描述
- 视觉参考 → 转成视觉和交互描述的 DSL(描述页面布局、时长、分块等),同时传入文字和图片信息
- 架构图 → 直接转化成需求放入 PRD
- 视觉稿 → 转成 NASL DSL,注入上下文生成页面
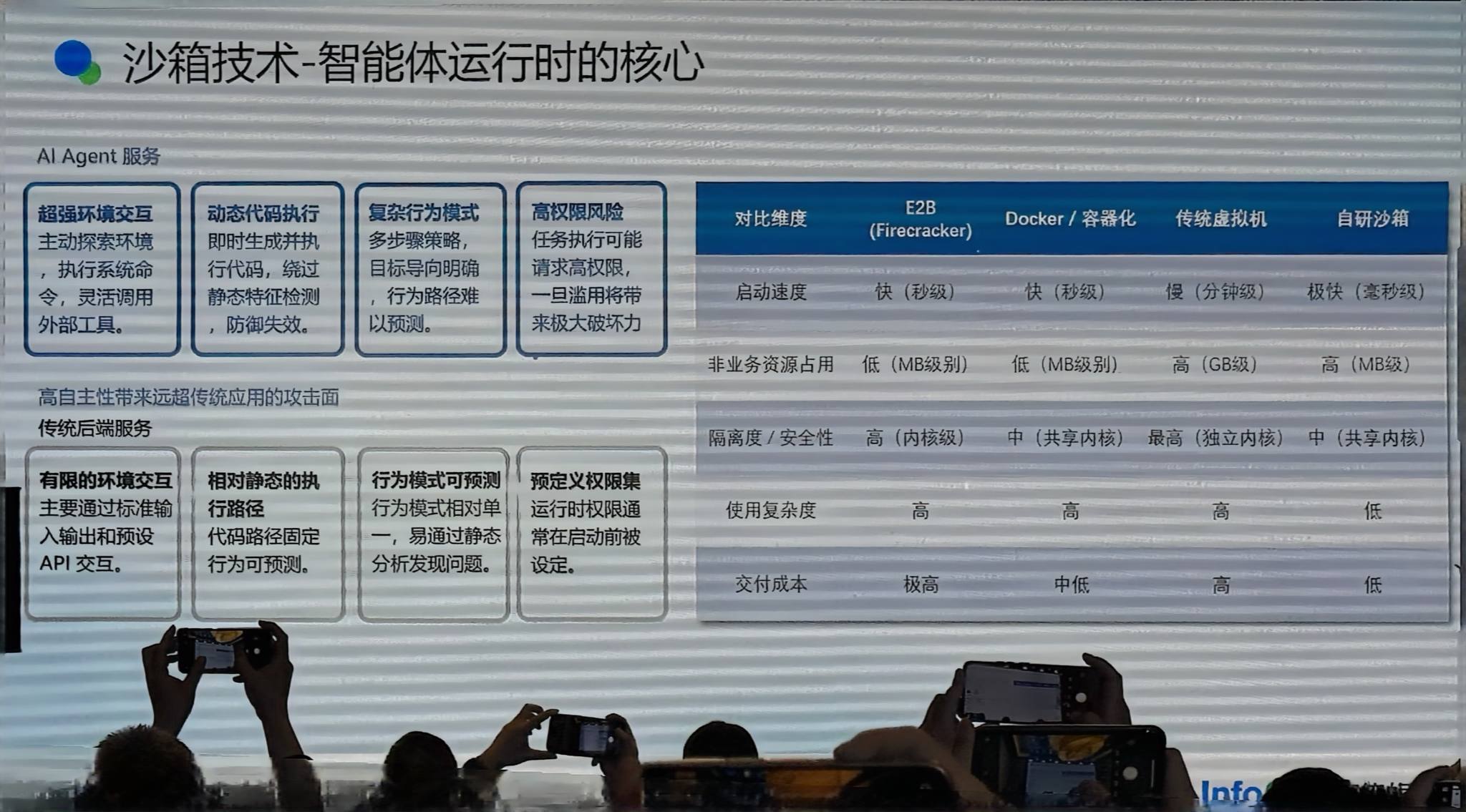
沙箱技术:Bubblewrap
AI Agent 的行为非常复杂,会遇到 AI 把自己代码删掉、清空数据库等情况,必须有强隔离能力管理 AI 执行环境。
我们对比了多个方案:
- E2B:Manus 早期采用,低资源占用、高隔离,但无法私有化部署
- Docker/虚拟机:部署成本高
- 最终选择:参考 Claude Code 的沙箱模式,使用 Linux namespace(Bubblewrap) 做自然沙箱
优点:不需要很强的权限,启动非常快,命令行结构高效。适合 AI Agent 的沙箱需求。
架构:Sandbox Manager → 唤起沙箱 → 每个服务器集群有 Sandbox Proxy(创建销毁沙箱)→ 每台机器有 Sandbox Instance(管理沙箱状态和启停)→ 从 3 个 Sandbox Process 收集状态,由 Manager 统一管理。
Harness Engineering 设计原则总结
- 每个 Skill 对应一个 Sub-agent,保证上下文隔离
- 主 Agent 只负责调度,甚至用 Workflow 方式
- 每个 Sub-agent 只干自己的事,状态共享全通过文件
- Context Offload:把上下文卸载到文件,保障任务在各阶段可干预和修改
- 每个结果都需要可验证,通过 Validator/Hooks 保证
- 一旦生成错误,验证失败,防止错误向后传播
三要素:智能体架构选择 + 任务管理 + 结果验证

五、Benchmark 体系:数据驱动产品与模型训练
核心原则:No Data No BB
没有 Benchmark,不知道产品边界、模型能力。我们对所有 AI 功能都建立了 Benchmark:需求解析、图片识别、需求标准化、技术设计、组件扩展、外部依赖等。
AI 提效的量化
单一功能提效率 = (手工开发时长 - AI 功能耗时) / 手工开发时长
从开发效率、需求排单度、代码数量等维度综合计算。

代码大模型训练
选择基座模型的标准:代码生成能力、评测及推理能力(推理能力很多 Benchmark 没考虑,但代码生成需要大模型真正理解代码语义)。
我们选择了 Qwen2.5-Coder 作为模型基础,效果非常好。
训练流程:
- 从开源社区收集代码,转成 NASL 指令格式(指令构造)
- 建立语言运行沙箱,通过 OSS 合成训练数据
- 数据后处理
- SFT(监督微调)+ 采样代码方案
- DPO 偏好对齐:构造(问题, 正确代码, 错误代码)三元组,强化训练过程。Bad case 比 Good case 更有效。
效果:通过工程修复和模型微调,HumanEval 中文得分从前沿的 5% 提升到 80%。

AI 工程化平台:闭环迭代
Benchmark → 识别产品边界(technology product fit)→ 上线后观测 bad case → 回流到训练平台 → 产品功能升级或模型迭代。
六、总结
Spec Driven 的本质:通过形式化来”降熵”。
- 原始需求:混沌阶段,不可控,熵值最高
- 需求标准化后:原始需求关注度下降
- 加入交互稿和设计稿:视觉和交互的扩展率下降
- 通过代码约束:整个输入输出可观测
Spec Driven 并不是高深的理念,只是通过形式化方式降低混乱程度的过程。

CodeWave 可视化软件工厂 vs AI Coding IDE:前者具备所见即所得、资产沉淀、生命周期管理、大促售货等企业级能力。

未来规划:
- Spec 与代码的双向绑定(改了代码同步更新 Spec,避免 Spec 失效)
- 优化生成速度
- 国产模型适配(Claude 限流封号问题严重)
- 与低代码平台更深度结合
Q&A
观众:为什么要用 NASL 这样的 DSL,而不是直接用大模型能力加上企业规范生成代码?
姜天意:约束性。直接用自然语言描述规范,很多细节说不清楚——数据库结构、关联关系、多步骤接口调用顺序,用自然语言很难描述清楚。NASL 里已经把流程引擎、页面逻辑等细节定义清楚了。
另外,不能过度依赖大模型掌握所有企业知识。我们把它切分成很多领域,每个领域有独立文档,做动态召回,既节省上下文,也让生成更准确。
总结两点:第一,DSL 是限制模型输出的有效方式(以现在的实践来看是这样,半年后可能又不一样了);第二,有了 DSL 后,可以做很多工程优化,比如渐进式加载、渐进式披露。
观众:验证部分的具体逻辑是什么?服务搭好后怎么做自动验证?
姜天意:验证分三层:
- 语法验证:通过 Language Server 做语法校验
- 技术设计验证:基于技术设计里生成的 API 协议,直接生成测试用例,验证接口的输入输出
- 需求测试:基于每个 EARS feature 生成一对一的测试用例,与业务功能点关联。跑完代码逻辑后,基于生成的一对一测试再跑业务验证
第三层比较靠后,需要测试介入,因为自动生成的一对一测试可能缺少异常流和边界情况,需要基于生成的测试定义做二次关联处理。
前端界面验证:因为我们用 NASL,很多交互逻辑已经在 NASL 里定义清楚了,可以用 AI 直接驱动,可验证性相对简单。